PerplexityBot: qué es el crawler de Perplexity y cómo controlar el rastreo del sitio
Por Tiago CostaActualizado el 2 de julio de 2026
PerplexityBot es el rastreador de Perplexity, el buscador con IA que responde preguntas citando fuentes. En la práctica, PerplexityBot:
- visita páginas públicas y las indexa para su consulta;
- ayuda a Perplexity a armar respuestas con enlaces a los orígenes;
- se identifica con el user-agent PerplexityBot en los registros del servidor;
- debe respetar el robots.txt, que es donde permites o bloqueas el acceso.
Qué es el PerplexityBot
El PerplexityBot es el rastreador automatizado de Perplexity, una herramienta que mezcla búsqueda e inteligencia artificial para responder preguntas en lenguaje natural, siempre con enlaces a las fuentes. Para que esa respuesta con citas exista, Perplexity necesita antes conocer el contenido de la web, y ahí entra el bot.
Como todo crawler, el PerplexityBot recorre páginas públicas, lee el texto y lo guarda en un índice. La diferencia frente a un rastreador de entrenamiento puro está en el uso: el material sirve para que Perplexity encuentre y cite información actual al responder, no solo para entrenar un modelo de una vez. Por eso el PerplexityBot valora el contenido fresco y bien estructurado.
Para quien publica en la web, esto cambia la lógica de la decisión. Bloquear el PerplexityBot protege el contenido, pero también saca tu sitio de la lista de fuentes que Perplexity puede citar, con enlaces que traen visitas de vuelta.
PerplexityBot y Perplexity-User: dos agentes, dos propósitos
Un detalle que confunde a mucha gente es que Perplexity opera más de un agente, y cada uno se comporta de un modo. Entender la diferencia es esencial para escribir reglas que hagan lo que esperas:
- PerplexityBot: el rastreador que indexa la web de forma sistemática para abastecer el índice del buscador. Es el que controlas en el robots.txt.
- Perplexity-User: lanza una visita a una página concreta cuando un usuario hace una pregunta que exige revisar esa dirección en tiempo real. Al actuar a pedido de una persona, Perplexity trata ese acceso de forma distinta al rastreo masivo.
Esta distinción tiene consecuencias prácticas. Una regla que frena al PerplexityBot puede no afectar al agente que busca a pedido del usuario, lo que suele ser fuente de malentendidos sobre bloqueos que parecen no funcionar.
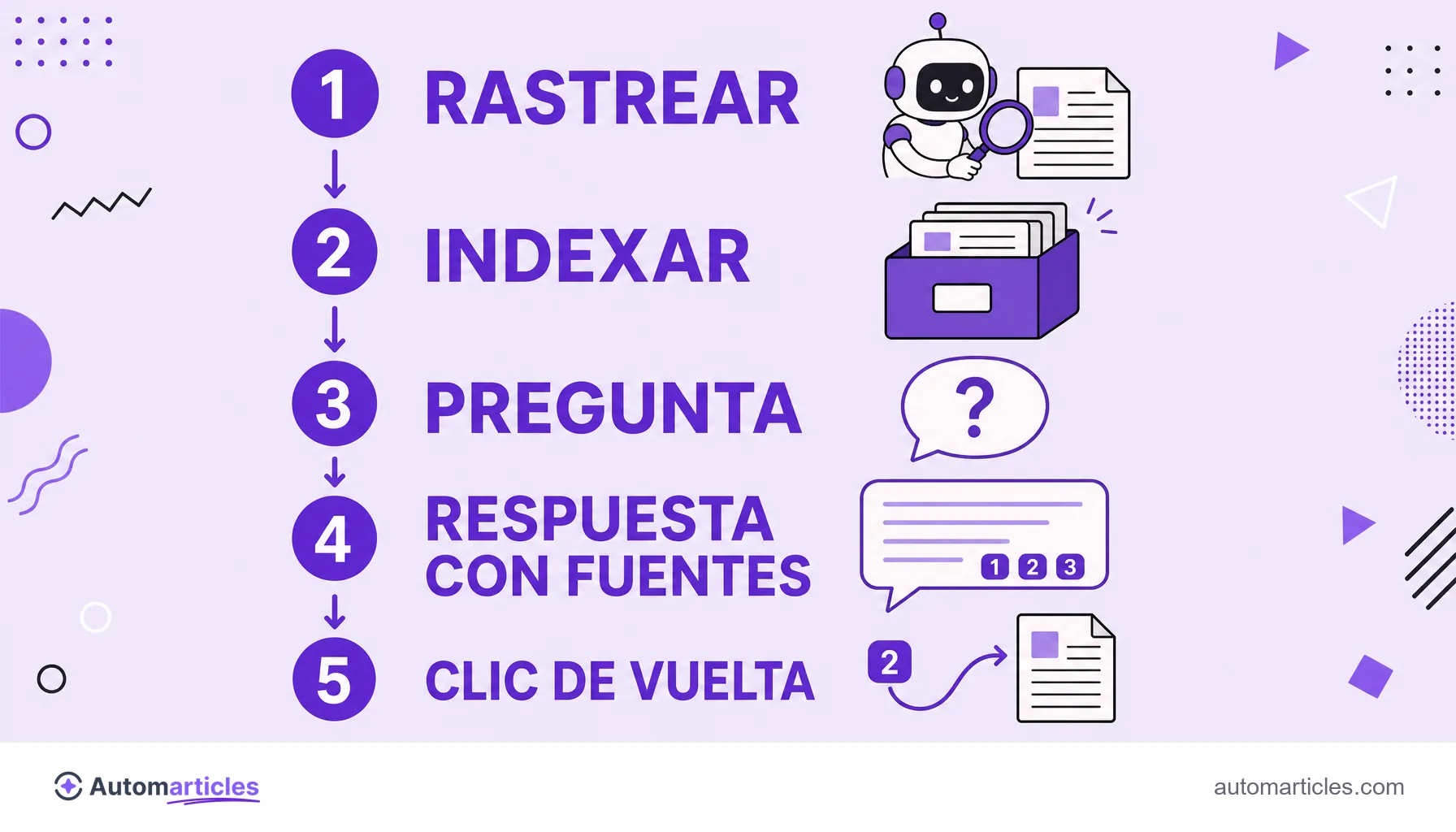
Cuál es el user-agent del PerplexityBot
En los registros (logs) de tu servidor, el rastreador de Perplexity aparece con un user-agent que contiene la palabra PerplexityBot, en un formato parecido a PerplexityBot/1.0 acompañado de una dirección de contacto de Perplexity. El agente lanzado por usuario aparece con el identificador Perplexity-User.
Saber leer ese identificador es el primer paso para monitorear cuánto rastrea Perplexity tu sitio y para confirmar si un acceso es realmente suyo. Recuerda que el user-agent es solo un texto declarado por el propio visitante, así que puede copiarse. La confirmación sólida viene de cruzar el nombre con los rangos de IP oficiales y con el comportamiento del acceso, y no solo de la línea que aparece en el log.
Cómo permitir o bloquear el PerplexityBot en robots.txt
El punto de control principal es el archivo de robots.txt, en la raíz del sitio. Para bloquear el rastreo del PerplexityBot, usa:
- User-agent: PerplexityBot
- Disallow: /
Para permitirlo, basta con no bloquear, o usar Allow: /. Si también quieres frenar el agente lanzado por usuario, necesitas una regla específica para el Perplexity-User, sabiendo que Perplexity sostiene que las búsquedas hechas a pedido de una persona funcionan como un navegador que actúa por ella.
Aquí hay un aviso importante: el robots.txt depende de la buena voluntad del bot. Y, en el caso de Perplexity, esa buena voluntad fue puesta en duda, como muestra la siguiente sección. Para contenido que de verdad necesitas proteger, el robots.txt por sí solo puede no bastar.
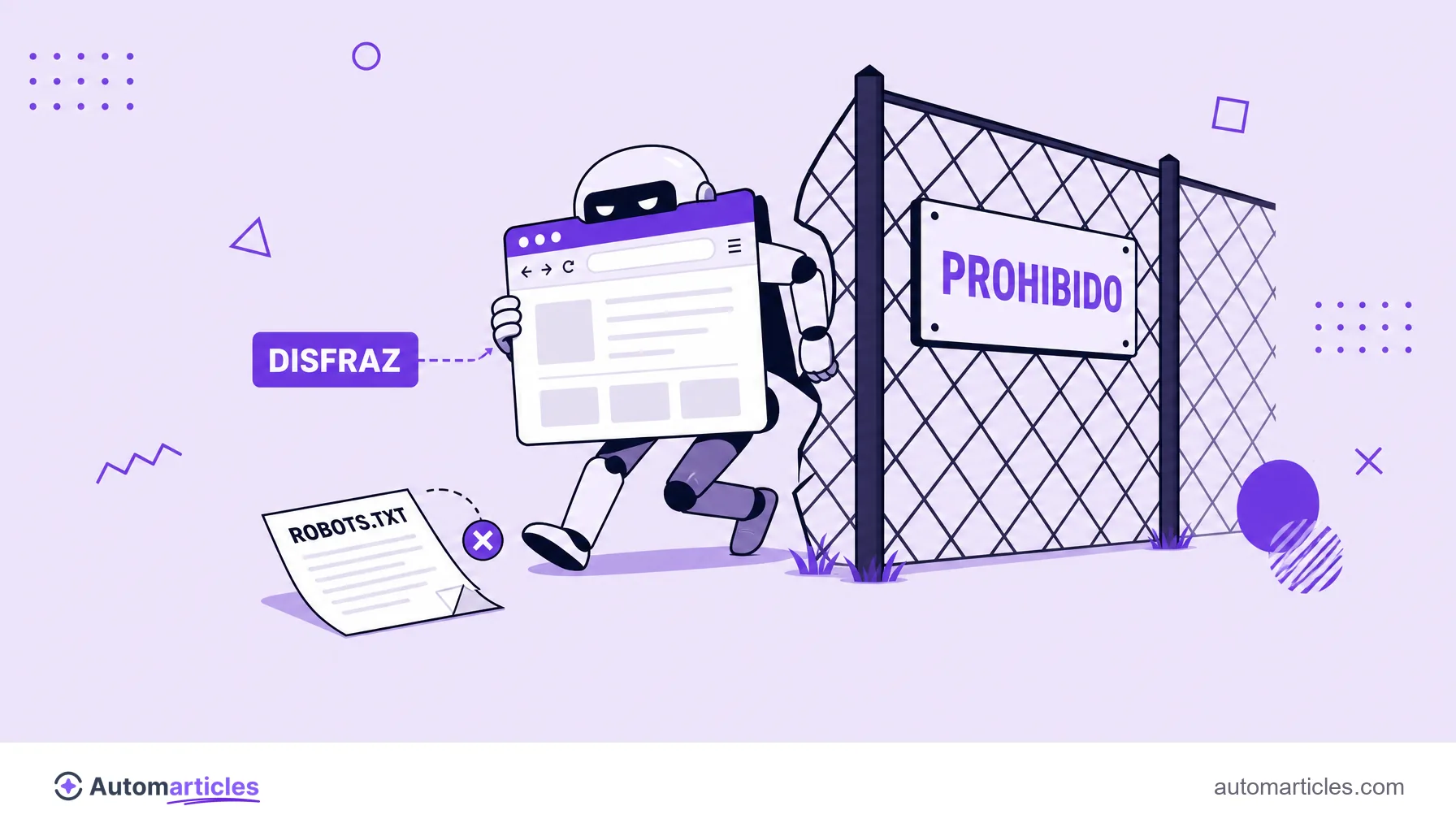
La polémica del rastreo furtivo de Perplexity
No todo el rastreo de Perplexity ocurrió a la luz del día. En 2025, Cloudflare publicó una investigación afirmando que, cuando los bots declarados de Perplexity encontraban bloqueos, la empresa recurría a rastreadores no declarados que se disfrazaban de un navegador Chrome común para acceder a contenido de sitios que habían pedido no ser rastreados. Según Cloudflare, este comportamiento se observó en decenas de miles de dominios y llegaba a millones de peticiones por día.
Cloudflare relató haber creado dominios nuevos y no divulgados, configurados para negar el acceso a todos los bots, y aun así Perplexity habría conseguido recuperar y mostrar el contenido de esos sitios de prueba. En respuesta, Perplexity cuestionó la acusación, alegando que parte del tráfico atribuido a él venía de un servicio de terceros y que sus búsquedas a pedido de usuario actúan como un navegador, no como un raspador de entrenamiento.
Al margen de cómo termine el debate, la lección para quien tiene un sitio es clara: el robots.txt es una orientación, no una barrera física. Si el objetivo es impedir el acceso de verdad, y no solo señalar la preferencia, hace falta refuerzo técnico en el servidor o en un firewall de aplicación.
PerplexityBot y GEO: convertirse en una fuente citada
Desde el punto de vista del GEO (Generative Engine Optimization), Perplexity es uno de los objetivos más interesantes, justamente porque cita y enlaza las fuentes de las respuestas. Cada cita es una oportunidad real de aparecer ante el usuario y de recibir un clic de vuelta, algo que no todo asistente de IA ofrece.
Para ser candidato a ese tipo de cita por IA, el camino empieza por permitir el PerplexityBot y seguir las buenas prácticas de contenido para motores de respuesta: responder la pregunta de forma directa al inicio, respaldar las afirmaciones con datos y fuentes, y organizar el texto en bloques fáciles de extraer. El contenido actual y específico tiende a ser preferido, ya que Perplexity se centra en responder con información reciente.
Como señal complementaria, el archivo de llms.txt viene siendo adoptado para indicar a los modelos qué contenido del sitio priorizar. No obliga a nada, pero ayuda a comunicar organización e intención a quien quiere ser bien representado en las respuestas de IA, en vez de simplemente desaparecer de ellas.