Qué es un crawler (web crawler) y cómo funciona en el SEO
Por Tiago CostaActualizado el 2 de julio de 2026
Un crawler (o web crawler) es el robot que los buscadores usan para descubrir y leer las páginas de la web. En la práctica, un crawler:
- parte de una lista de URLs conocidas y visita cada página;
- lee el contenido y sigue los enlaces para hallar nuevas páginas;
- envía lo que encuentra al índice del buscador;
- respeta instrucciones como el robots.txt y la etiqueta noindex.
Qué es un crawler y cómo funciona
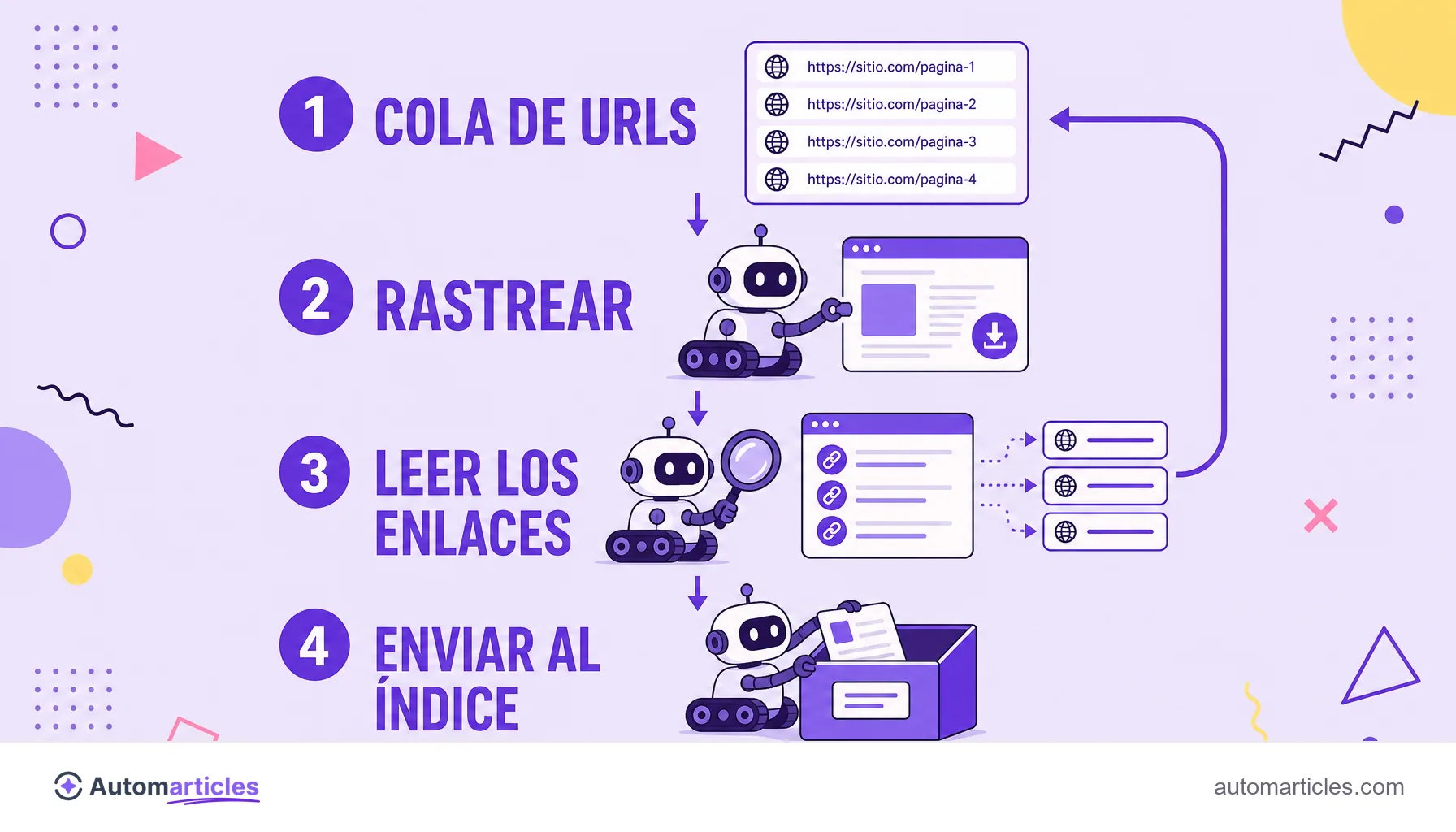
Un crawler es un programa automatizado que navega por la web de forma sistemática, saltando de enlace en enlace para descubrir y leer páginas. Recibe varios nombres que significan lo mismo: web crawler, spider (araña), robot o bot. El más famoso de todos es Googlebot, el rastreador del motor de búsqueda de Google.
El funcionamiento es un ciclo sencillo que se repite a escala gigantesca. El crawler empieza con una lista de URLs que ya conoce, visita cada una, lee el HTML de la página, extrae todos los enlaces encontrados y añade las nuevas direcciones a una cola para visitarlas después. Así, página tras página, cartografía toda la web.
La escala de ese trabajo es difícil de imaginar. Según la documentación de Google sobre cómo funciona la Búsqueda, el índice alimentado por estos rastreadores ya cubre cientos de miles de millones de páginas y ocupa más de 100 millones de gigabytes. Todo eso empieza con el paso más simple: un robot visitando una dirección.
Rastreo, indexación y posicionamiento: dónde entra el crawler
Es común confundir el trabajo del crawler con el buscador entero, pero es solo la primera de tres etapas. Entender esa división evita muchos errores de SEO:
- Rastreo (crawling): el crawler encuentra y descarga la página. Aquí es donde entra el robot.
- Indexación: el buscador analiza el contenido descargado y lo guarda en el índice. Mira el proceso de indexación en detalle.
- Posicionamiento: cuando alguien busca, el buscador ordena las páginas ya indexadas por relevancia.
La consecuencia práctica importa: ser rastreado no garantiza ser indexado, y ser indexado no garantiza posicionar bien. Pero nada ocurre sin la primera etapa. Si el crawler no consigue acceder a una página, simplemente no existe para el buscador, por muy bueno que sea el contenido.
Los principales crawlers de la web (y los nuevos bots de IA)
Cada gran plataforma tiene su propio crawler, y conocer los principales ayuda a interpretar los accesos que aparecen en los registros del servidor. Los más relevantes hoy:
| Crawler | De quién es y para qué sirve |
|---|---|
| Googlebot | Rastreador de Google, alimenta el mayor índice de búsqueda del mundo. |
| Bingbot | Rastreador de Bing, de Microsoft. |
| GPTBot | Bot de OpenAI, recopila contenido para entrenar modelos de IA. |
| ClaudeBot y PerplexityBot | Rastreadores de asistentes de IA que buscan contenido para responder y citar. |
La gran novedad de los últimos años fue justamente la llegada de los crawlers de inteligencia artificial. Además de buscar para indexar, buscan para entrenar modelos y para generar respuestas en tiempo real, lo que convierte la decisión de permitir o bloquear cada bot en una elección estratégica de contenido.
Cómo controlar a qué accede el crawler
No estás a merced del crawler: existen varias formas de orientar por dónde pasa y qué hace con lo que encuentra. Las principales herramientas:
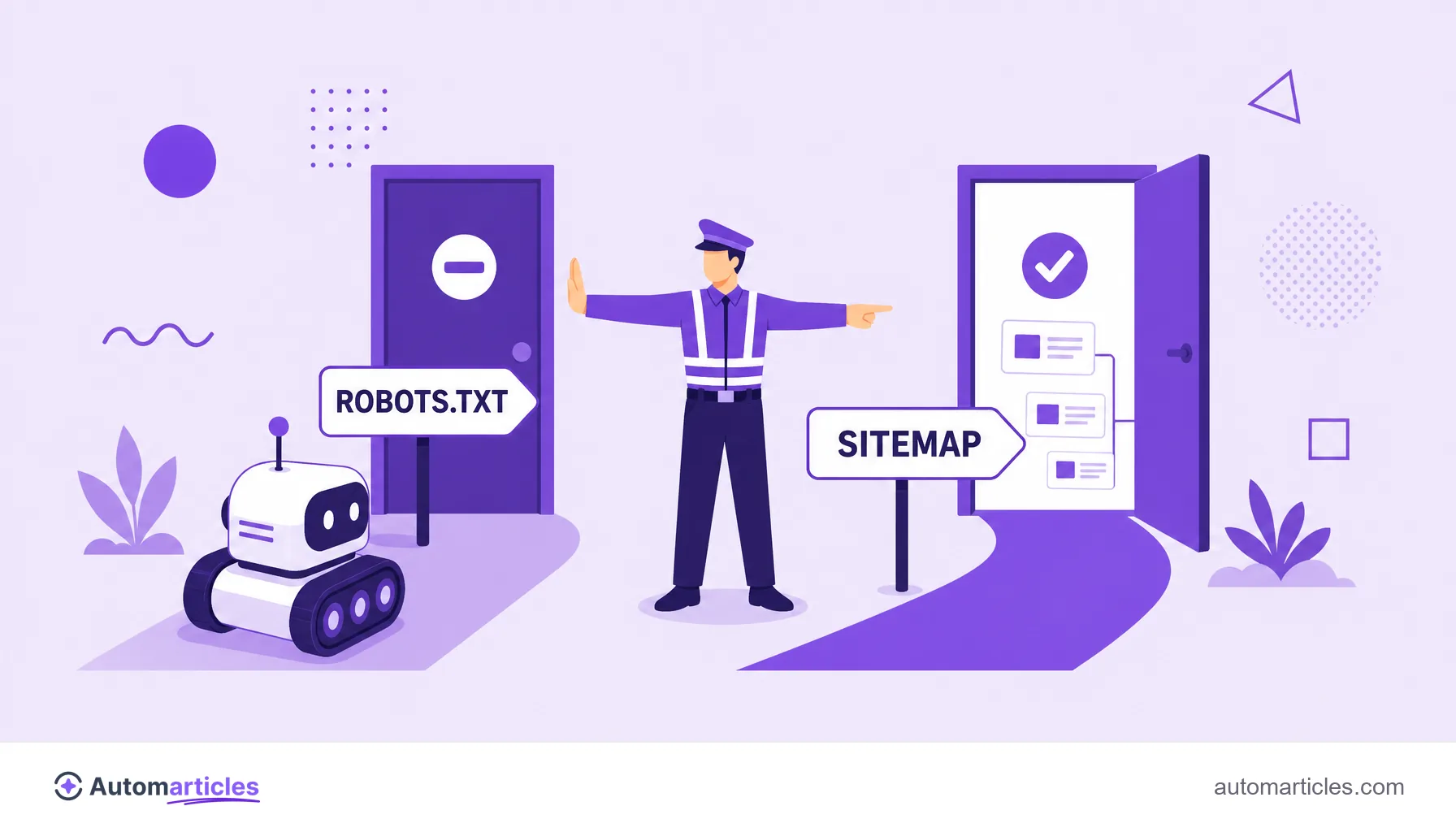
- robots.txt: el archivo de robots.txt indica a los robots qué áreas del sitio pueden o no rastrear.
- Sitemap: el sitemap XML entrega al crawler una lista organizada de las URLs importantes, facilitando el descubrimiento.
- Presupuesto de rastreo: en sitios grandes, cuidar el crawl budget garantiza que el robot gaste su tiempo en las páginas que importan.
- Noindex: la directiva de noindex deja que el crawler lea la página, pero pide que quede fuera del índice.
Una advertencia que vale oro: robots.txt y noindex resuelven problemas diferentes. El robots.txt impide el rastreo; el noindex impide la indexación. Bloquear en el robots.txt una página que querías desindexar impide que el robot vea el noindex, y el tiro sale por la culata.
¿Un crawler es un delito? Bots buenos y bots malos
Rastrear la web pública no es, en sí, ilegal. Los buscadores lo hacen todo el tiempo, y es gracias a estos robots que internet es buscable. La línea entre un bot legítimo y uno problemático está en el comportamiento, no en la tecnología.
Un crawler bueno se identifica, respeta el robots.txt, controla la frecuencia de acceso para no sobrecargar el servidor y recopila solo contenido público. En cambio, prácticas como ignorar el robots.txt, raspar datos personales o protegidos, saltarse inicios de sesión o tumbar un sitio con exceso de peticiones sí pueden violar términos de uso y leyes, y ahí es donde vive el riesgo.
La dimensión del tráfico automatizado ayuda a entender la preocupación. El informe de bots de Imperva estimó que casi la mitad de todo el tráfico de internet (49,6% en 2023) vino de robots, no de personas. No todo bot es bienvenido, por eso saber distinguir el rastreador de un buscador de un raspador abusivo es parte del trabajo de quien gestiona un sitio.
Cómo facilitar el trabajo del crawler en tu sitio
Cuanto más fácil sea para el crawler encontrar y entender tus páginas, mayor es la probabilidad de que se indexen rápido. Una lista práctica:
- Mantén un sitemap actualizado: es el mapa que apunta al robot hacia las páginas correctas.
- Cuida los enlaces internos: las páginas sin ningún enlace apuntando a ellas (las huérfanas) difícilmente se descubren.
- Cuida la velocidad: las páginas que cargan rápido permiten que el robot rastree más en menos tiempo.
- Evita los callejones sin salida: corrige enlaces rotos y cadenas de redirección que desperdician el rastreo.
- Comprueba el acceso: la herramienta de inspección de URL muestra cómo ve Googlebot una página concreta.
Al final, ayudar al crawler es ayudarte a ti mismo. Una arquitectura limpia, rápida y bien enlazada es fácil de leer para los robots y, no por casualidad, también ofrece una mejor experiencia para las personas.