URL canónica: qué es y cómo resolver el contenido duplicado
Por Tiago CostaActualizado el 2 de julio de 2026

La URL canónica es la versión preferida de una página que el buscador debe indexar cuando existen direcciones duplicadas. En la práctica, la URL canónica:
- se indica con la etiqueta rel=canonical en el HTML de la página;
- dice a Google qué dirección tratar como la original;
- concentra en esa versión la autoridad de los enlaces;
- resuelve el contenido duplicado sin eliminar las demás páginas.
Qué es una URL canónica
La URL canónica es la dirección que eliges como la versión oficial de una página cuando el mismo contenido, o un contenido muy parecido, puede alcanzarse por más de una URL. En lugar de dejar que el buscador decida solo cuál mostrar, señalas la preferida, y las demás pasan a tratarse como copias que remiten a la original.
La indicación se hace con una etiqueta llamada rel="canonical", colocada en el head HTML de las páginas duplicadas. Funciona como una nota para el buscador: la versión que vale para la indexación y para posicionar es esta, no las otras. El término viene de canónico, en el sentido de oficial, lo que sirve de referencia.
Conviene tener cuidado con el vocabulario: encontrarás canonical, etiqueta canonical y URL canónica hablando de lo mismo. Todos se refieren al mismo mecanismo de elegir y señalar la versión principal de un contenido.
Por qué el contenido duplicado es un problema
El contenido duplicado ocurre cuando el mismo texto aparece en direcciones diferentes, ya sea por versiones con y sin www, parámetros de seguimiento, páginas de producto que se repiten o versiones para imprimir. Para el buscador, esto crea una duda: ¿cuál de esas URL debe aparecer en los resultados?
El problema es más común de lo que parece. Un estudio de Semrush, que analizó 100.000 sitios y 450 millones de páginas, señaló el contenido duplicado como el problema de SEO más frecuente, presente en cerca de la mitad de los sitios revisados. Es decir, es una trampa que alcanza a la mayoría de los proyectos en algún momento.
Cuando Google encuentra varias copias sin orientación, puede repartir la fuerza de los enlaces entre ellas, elegir la versión equivocada para mostrar o simplemente gastar presupuesto de rastreo visitando páginas redundantes. La URL canónica resuelve esto concentrando las señales en una única dirección.
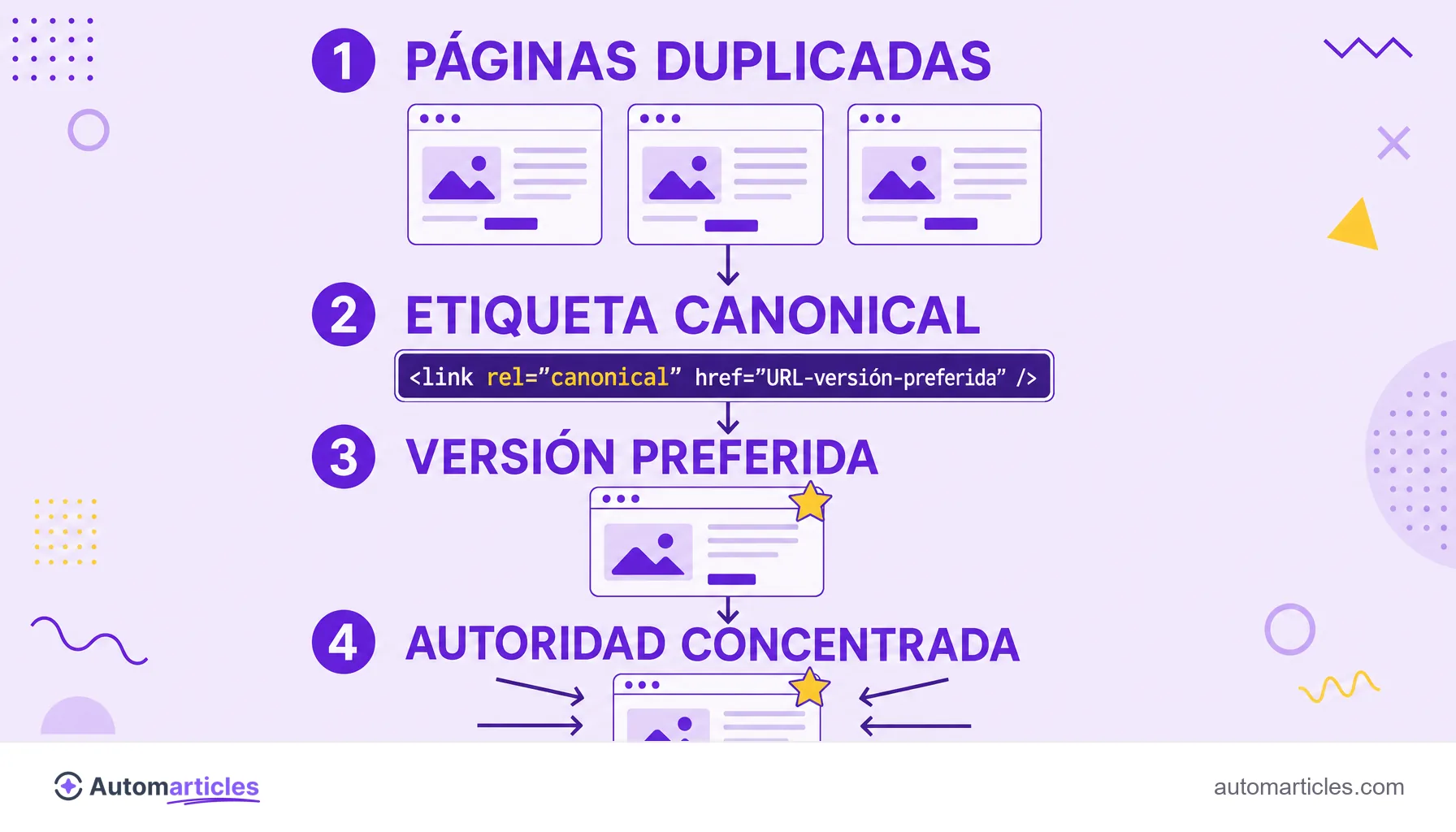
Cómo funciona la etiqueta canonical
La etiqueta canonical es una línea simple en el HTML, pero su efecto es grande. El formato es este: <link rel="canonical" href="https://tusitio.com/pagina-oficial">, insertado dentro de la sección <head> de cada versión duplicada, apuntando a la URL preferida.
Al leer ese marcado, el buscador consolida las páginas duplicadas en la canónica. En la práctica, esto significa que la fuerza transmitida por los enlaces (el llamado link juice) y la relevancia medida por algoritmos como el PageRank se concentran en la dirección oficial, en vez de repartirse entre copias.
Dos puntos merecen atención. Primero, la etiqueta canonical es una sugerencia fuerte, no una orden absoluta: Google puede elegir otra versión si las señales apuntan allí. Segundo, una página puede apuntarse a sí misma como canónica, práctica recomendada para dejar claro cuál es la versión principal.
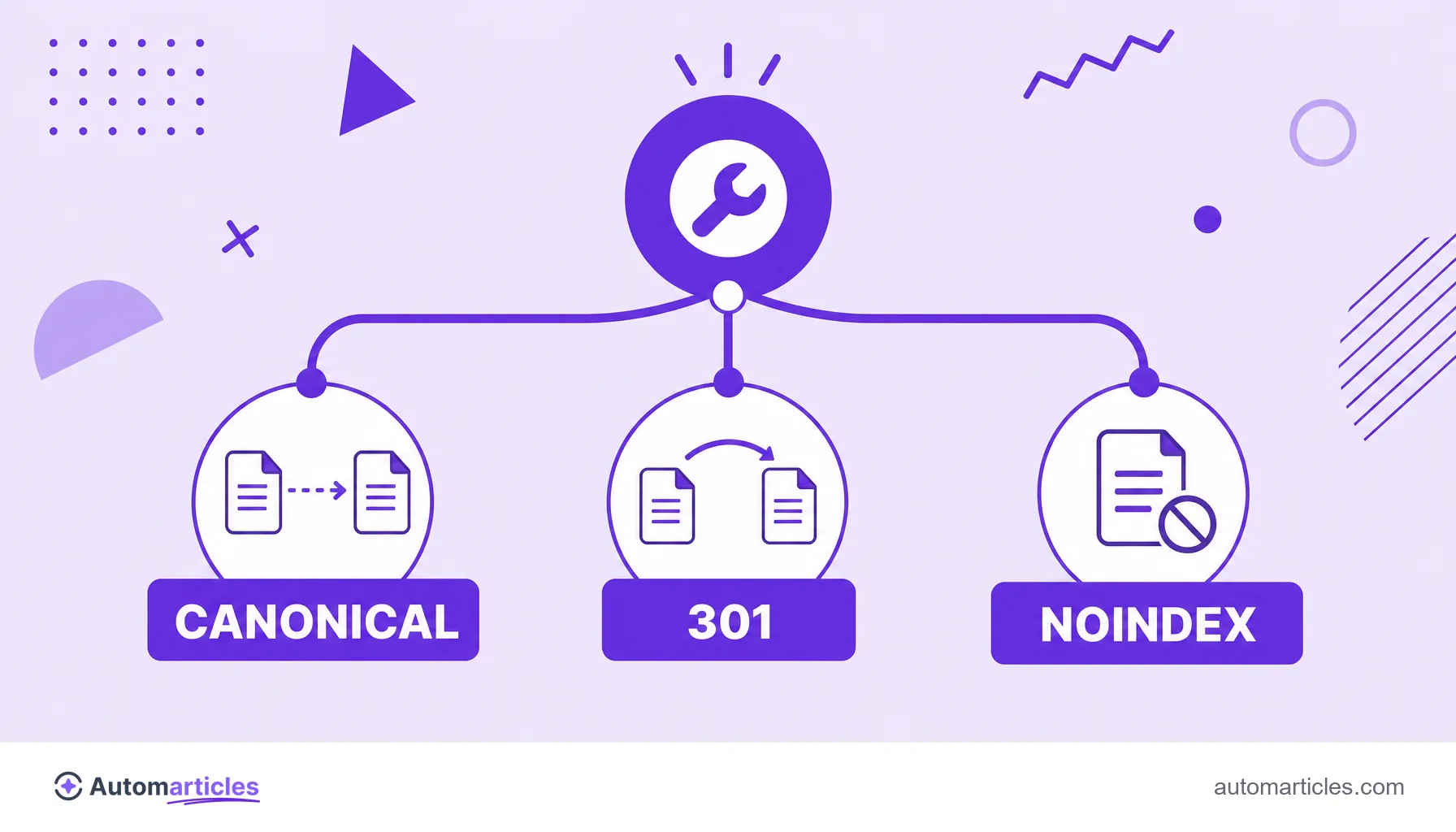
URL canónica, redirección y noindex: cuándo usar cada uno
Canonical no es la única forma de lidiar con páginas parecidas, y elegir la herramienta equivocada cuesta tráfico. La regla general separa tres situaciones:
| Situación | Herramienta ideal |
|---|---|
| Contenido duplicado que debe seguir accesible | Etiqueta canonical apuntando a la versión preferida |
| Página que cambió de dirección de forma permanente | Redirección 301 |
| Página que no debe aparecer en la búsqueda de ningún modo | Directiva noindex |
La diferencia importa: canonical mantiene ambas páginas activas y solo señala la preferida; la redirección 301 lleva al usuario y al buscador a la nueva dirección; y el noindex saca la página de los resultados sin consolidar autoridad. Mezclar canonical con noindex en la misma página, por cierto, envía señales contradictorias y debe evitarse.
Errores comunes con la etiqueta canonical
La etiqueta canonical es potente precisamente porque es fácil de equivocar. Los deslices más frecuentes son:
- Apuntar a la URL equivocada: canónicas que remiten a páginas inexistentes, rotas o irrelevantes confunden al buscador.
- Canonical en cadena: la página A apunta a la B, que apunta a la C, creando un circuito que debilita la señal.
- Bloquear la canónica en robots.txt: si el buscador no puede rastrear la URL preferida, no lee la instrucción.
- Ignorar los parámetros de URL: filtros y ordenaciones generan muchas direcciones que necesitan canonical, como explica la entrada de parámetros de URL.
- Confundirla con hreflang: las versiones en idiomas diferentes no son duplicados y deben usar hreflang, no una canonical de una a otra.
Un mensaje famoso de Google Search Console, el que dice que el buscador eligió una canónica distinta de la indicada, suele nacer justamente de estos errores: las señales de la página contradicen la etiqueta.
Cómo comprobar la URL canónica de una página
Comprobar si la canónica es correcta es rápido y evita sorpresas en el ranking. Una rutina simple:
- Mira el código fuente: busca en el HTML la línea rel="canonical" y confirma a qué URL apunta.
- Usa la inspección de URL: la herramienta de inspección de URL muestra la canónica declarada por la página y la que Google eligió de verdad.
- Sigue el informe de indexación: en Google Search Console puedes ver qué páginas se consolidaron en otra canónica.
- Comprueba la consistencia: asegúrate de que la canónica, el sitemap y los enlaces internos apunten todos a la misma versión preferida.
Cuando la canónica declarada y la que Google eligió coinciden, es señal de que la página envía señales claras. Cuando difieren, conviene investigar qué señal está llevando al buscador hacia otra URL.