Noindex: qué es y cómo usarlo para bloquear la indexación
Por Tiago CostaActualizado el 2 de julio de 2026

Noindex es una directiva que evita que una página aparezca en los resultados de búsqueda. En la práctica, el noindex:
- se aplica mediante una meta etiqueta robots o la cabecera HTTP X-Robots-Tag;
- hace que el buscador retire la página del índice, aun con enlaces apuntando a ella;
- exige que la página siga siendo rastreable, para que el robot lea la instrucción;
- no debe combinarse con un bloqueo en el robots.txt.
Qué es el noindex y qué hace la directiva
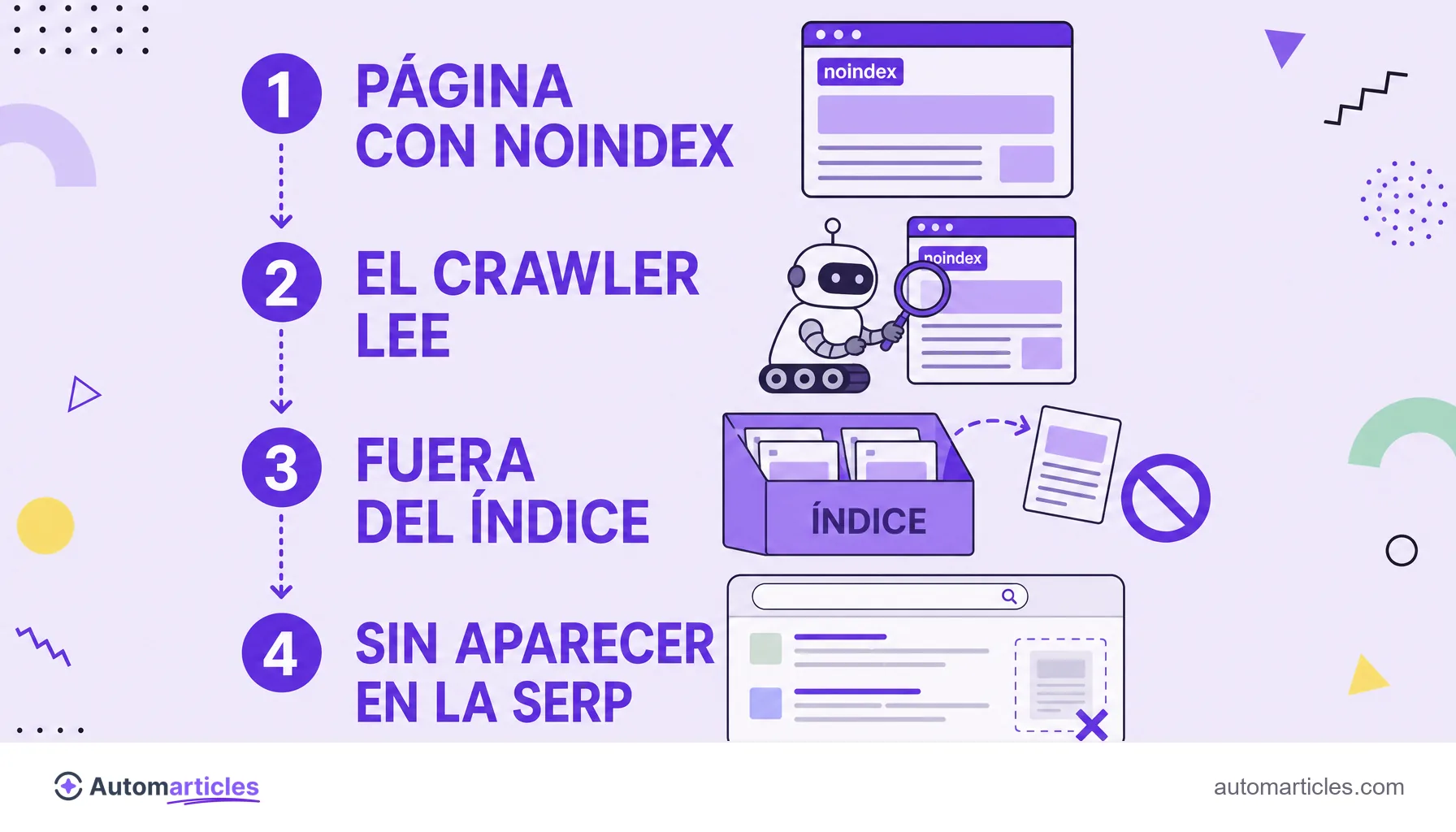
Noindex es una instrucción que añades a una página para indicar a los motores de búsqueda que no debe aparecer en los resultados. Es una directiva de robots: cuando Google rastrea la página y encuentra el noindex, retira esa URL del índice y deja de mostrarla en la búsqueda, aunque otras páginas la enlacen.
Para entender el noindex, ayuda separar dos procesos. Primero viene el rastreo, cuando el robot del buscador visita la página. Después viene la indexación, cuando el contenido se guarda en el índice para poder posicionar. El noindex actúa justo en ese segundo proceso: la página puede incluso ser visitada, pero queda fuera del índice.
Por eso el noindex es diferente de simplemente ocultar un contenido. La página sigue en línea, accesible para quien tiene el enlace, y todavía puede ser leída por el crawler. Lo que el noindex hace es una sola cosa, pero decisiva: sacar esa URL del escaparate de los resultados de búsqueda.
Cómo aplicar el noindex: meta etiqueta robots y cabecera HTTP
Existen dos formas oficiales de aplicar el noindex, y la elección depende del tipo de archivo que quieras bloquear.
- Meta etiqueta robots: la manera más común, usada en páginas HTML. Basta con añadir la línea <meta name="robots" content="noindex"> dentro de la sección <head> del código. Para hablar solo con Google, cambia robots por googlebot.
- Cabecera HTTP X-Robots-Tag: ideal para archivos que no son HTML, como PDF, imágenes u hojas de cálculo, donde no existe una sección <head> para alojar la meta etiqueta. En ese caso, la regla va en la respuesta del servidor, como explica la entrada sobre la cabecera X-Robots-Tag.
Ambas formas conviven con las demás meta etiquetas de la página y tienen el mismo efecto: en cuanto el buscador lee la instrucción, trata la URL como no indexable. La diferencia es solo dónde se encuentra la regla, en el HTML o en la respuesta del servidor.
Noindex vs robots.txt: el error clásico
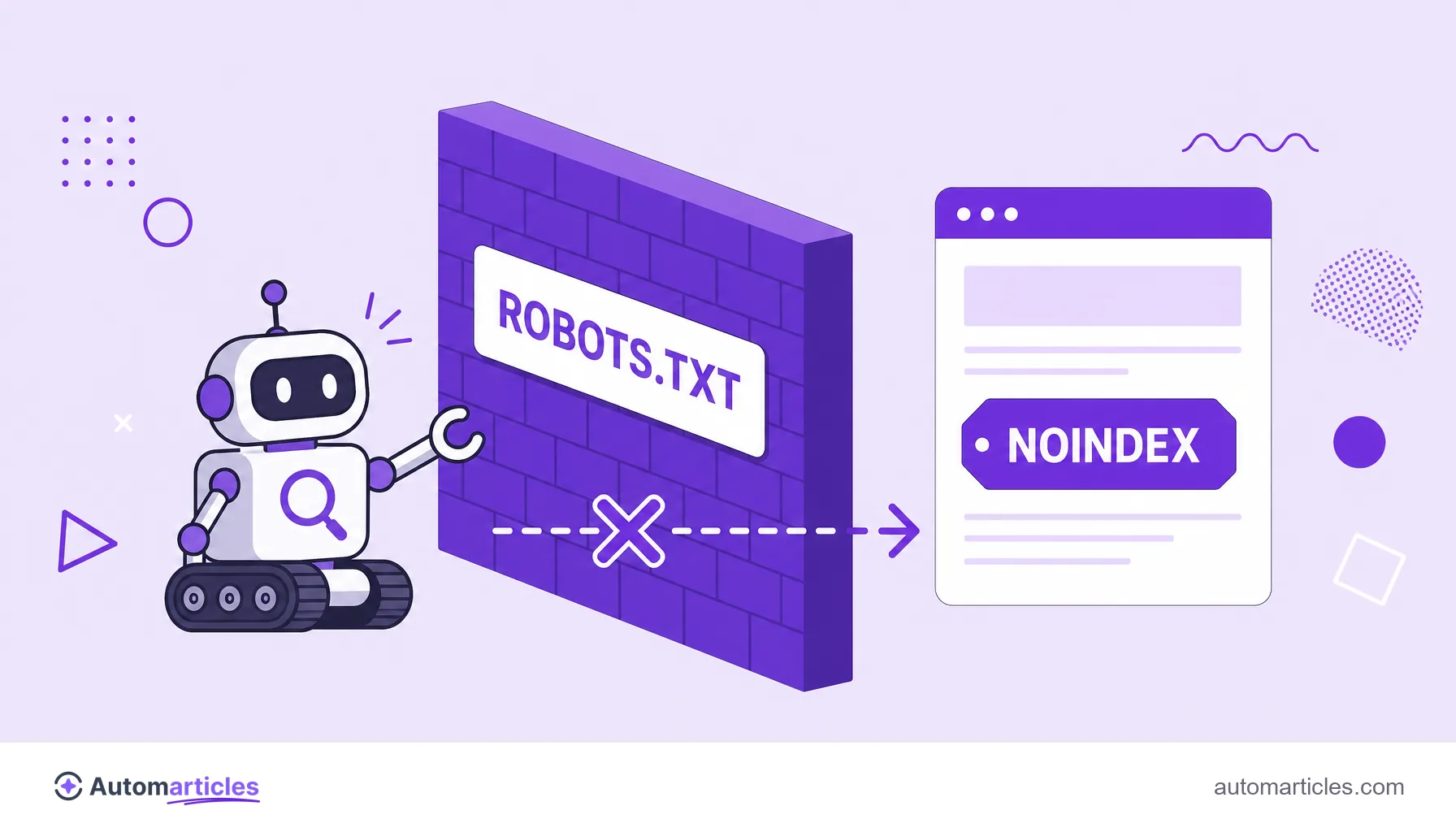
Este es el malentendido más común del SEO técnico, y hace caer páginas que deberían desaparecer mientras mantiene en línea páginas que deberían irse. La confusión nace porque noindex y robots.txt parecen hacer lo mismo, pero actúan en etapas diferentes.
- El robots.txt controla el rastreo: indica al robot qué URLs puede o no puede visitar.
- El noindex controla la indexación: indica al buscador que no guarde la página en el índice.
El detalle que lo rompe todo es este: para obedecer el noindex, el buscador necesita rastrear la página y leer la etiqueta. Si bloqueas esa misma URL en el robots.txt, el robot nunca llega a visitarla, nunca ve el noindex y, irónicamente, la página puede seguir apareciendo en la búsqueda (solo que sin descripción). Es decir, bloquear en el robots.txt una página que quieres desindexar es dispararte en el pie.
La regla práctica es directa: si el objetivo es sacar una página de los resultados, usa noindex y deja la URL libre para ser rastreada. El robots.txt sirve para ahorrar rastreo en áreas que ni siquiera necesitan ser leídas, no para desindexar.
Noindex y nofollow: qué hace cada valor
La meta etiqueta robots acepta más de un valor a la vez, separados por una coma. Además del noindex, el compañero más frecuente es el nofollow, que se ocupa de los enlaces de la página. Conviene conocer las combinaciones:
| Valor | Qué le indica al buscador |
|---|---|
| index, follow | Comportamiento por defecto: indexa la página y sigue sus enlaces. |
| noindex, follow | No indexes esta página, pero sigue los enlaces para rastrear las demás. |
| noindex, nofollow | No indexes la página ni sigas ninguno de sus enlaces. |
| index, nofollow | Indexa la página, pero no sigas los enlaces que contiene. |
En la mayoría de los casos, cuando solo quieres desindexar una página útil (como una página de agradecimiento que aún lleva al usuario a otros lugares), el valor recomendado es noindex, follow: la página sale de la búsqueda, pero el flujo de rastreo por los enlaces internos continúa.
Cuándo usar noindex (y cuándo no)
El noindex es una herramienta de higiene del índice. Sirve para mantener fuera de la búsqueda páginas que existen por motivos de usabilidad, pero que no deberían competir por tráfico. Casos típicos:
- Páginas de agradecimiento y confirmación: las que aparecen tras un registro o una compra.
- Resultados de la búsqueda interna del sitio: páginas generadas automáticamente que crean contenido repetido y de bajo valor.
- Páginas de etiqueta y archivos frágiles: en blogs y CMS, muchos de esos listados son contenido pobre sin utilidad para la búsqueda.
- Entornos de prueba y áreas administrativas: versiones de staging que no pueden filtrarse al índice.
Por otro lado, el noindex no lo resuelve todo. Para contenido duplicado que quieres consolidar (y no borrar de la búsqueda), el camino suele ser la URL canónica, que indica la versión preferida sin ocultar la página. Y nunca pongas noindex en páginas estratégicas: un noindex olvidado en producción es una de las formas más rápidas de hundir el tráfico de un sitio entero.
Cómo comprobar si el noindex está funcionando
Aplicar el noindex es fácil; comprobar que de verdad surte efecto es lo que separa el buen trabajo. Una rutina sencilla:
- Mira el código fuente: abre la página y busca en el HTML la meta etiqueta robots con el valor noindex, o revisa la cabecera HTTP de la respuesta.
- Asegúrate de que la URL es rastreable: confirma que no está bloqueada en el robots.txt, o el buscador nunca leerá la etiqueta.
- Usa la inspección de URL: la herramienta de inspección de URL muestra si Google ve la página como excluida por la etiqueta noindex.
- Haz seguimiento en el informe: en Google Search Console, el informe de indexación lista todas las URLs que salieron del índice por el noindex.
Una vez reprocesada la página, deja de aparecer en los resultados. El plazo varía según la frecuencia con que el buscador rastrea tu sitio, así que seguir el informe evita sorpresas.