SEO tecnico y SERP
La parte tecnica del sitio y las funciones de la pagina de resultados.
Google Search Console
Google Search Console (GSC) es una herramienta gratuita de Google que muestra cómo el buscador ve tu sitio. En ella sigues qué páginas están indexadas, cuántos clics e impresiones recibe cada contenido en la búsqueda, en qué palabras clave apareces y qué problemas técnicos pueden estar perjudicando tu rendimiento en los resultados orgánicos.

LCP
LCP, sigla de Largest Contentful Paint (mayor renderización de contenido), es una de las métricas de los Core Web Vitals de Google. Mide cuánto tarda en aparecer en pantalla el elemento visible más grande de la página, normalmente una imagen destacada o un bloque de texto grande, desde el inicio de la carga. Cuanto menor es el LCP, más rápido siente el usuario que la página cargó.

AMP
AMP es la sigla de Accelerated Mobile Pages, o páginas móviles aceleradas, un formato abierto creado por Google en 2015 para hacer que las páginas web carguen casi al instante en el móvil. En la práctica, AMP es una versión reducida de una página, escrita con reglas estrictas de HTML y JavaScript para pesar menos y renderizar más rápido, algo que fue decisivo para noticias y artículos en el móvil.

Error 404
El error 404 es el código de estado HTTP que el servidor devuelve cuando la página pedida no se encuentra en la dirección a la que se accede. Indica que la URL no existe (o ya no existe), sea porque se escribió mal, se eliminó o cambió de dirección. Por sí solo, el 404 es un comportamiento normal de la web, pero en exceso y en páginas importantes perjudica la experiencia del usuario y el SEO.

Error 500
El error 500, o Internal Server Error, es un código de estado HTTP que indica un fallo interno e inesperado en el servidor, algo que le impide entregar la página solicitada. A diferencia de un error 404, que apunta a una página inexistente, el 500 muestra que la dirección existe, pero algo en el servidor se rompió por el camino. Es un error genérico, es decir, señala el problema sin detallar la causa exacta.

INP
INP, sigla de Interaction to Next Paint (interacción hasta el siguiente renderizado), es una de las métricas de los Core Web Vitals de Google. Mide la responsividad de la página, es decir, cuánto tarda en responder visualmente después de que el usuario hace clic, toca o escribe. Cuanto menor es el INP, más rápida y fluida es la experiencia. El INP sustituyó al antiguo FID (First Input Delay) como métrica oficial de responsividad.

CLS
El CLS, sigla de Cumulative Layout Shift (cambio acumulativo de diseño), es la métrica de los Core Web Vitals de Google que mide la estabilidad visual de una página mientras carga. Cuantifica cuánto saltan de posición los elementos de forma inesperada, esa molestia de intentar pulsar un botón y ver que la página se mueve. Cuanto menor es el CLS, más estable y agradable es la experiencia.
Crawler
Un crawler es un programa robot que recorre la web de enlace en enlace, descargando y leyendo páginas para alimentar el índice de un buscador. También llamado spider, robot o bot, el ejemplo más conocido es Googlebot. El crawler es la primera etapa de la búsqueda: antes de que una página pueda ser indexada y posicionada, tiene que ser encontrada y leída por uno de estos rastreadores.
Sitemap XML
Un sitemap XML es un archivo en formato XML que lista las URLs importantes de un sitio para ayudar a los buscadores a descubrir, rastrear y priorizar esas páginas. Funciona como un mapa del sitio entregado a Google, indicando qué direcciones existen y, opcionalmente, cuándo se actualizaron, lo que resulta especialmente útil en sitios grandes, nuevos o con páginas poco conectadas por enlaces internos.

JSON-LD
JSON-LD (JavaScript Object Notation for Linked Data) es el formato que Google recomienda para agregar datos estructurados a una página, dentro de un bloque de script separado del contenido visible. En lugar de repartir el marcado por el HTML, reúne todo en un objeto JSON con el vocabulario de Schema.org, indicando al buscador de forma explícita qué representa cada dato (un autor, un precio, una valoración, una fecha) para habilitar resultados enriquecidos en la búsqueda.

Error 410
El error 410, o 410 Gone, es el código de estado HTTP que informa que una página se eliminó de forma permanente y no volverá. A diferencia del 404, que solo dice que la página no se encontró ahora, el 410 es una señal explícita de eliminación definitiva. Por ser más categórico, tiende a acelerar la desindexación de la dirección en los buscadores, algo útil cuando quieres sacar un contenido del índice de Google de una vez.
Hreflang
Hreflang es un atributo HTML que informa a los buscadores el idioma y, opcionalmente, la región de una página, para que muestren la versión correcta a cada usuario. En sitios con contenido en varios idiomas o dirigido a países diferentes, las etiquetas hreflang conectan las versiones equivalentes de una misma página y evitan que compitan entre sí o aparezcan ante el público equivocado. Es una pieza central del SEO internacional.

Código de estado HTTP
Un código de estado HTTP es el número de tres dígitos que el servidor devuelve a cada petición hecha por un navegador o por un robot de búsqueda, informando el resultado de esa solicitud. Se organiza en cinco clases: 1xx (informativo), 2xx (éxito, como el 200), 3xx (redirección, como el 301), 4xx (error del cliente, como el 404) y 5xx (error del servidor, como el 500). En SEO, estos códigos indican a los buscadores si una página puede indexarse, si fue movida o si está fuera de servicio.

Inspección de URL
La inspección de URL es la herramienta de Google Search Console que muestra, para cualquier página de tu sitio, si está indexada, cómo la rastreó Google, qué URL eligió como canónica y si hay problemas que impiden que la página aparezca en la búsqueda. Es el examen de diagnóstico página por página, usado tanto para comprobar el estado actual como para solicitar la indexación de contenidos nuevos o actualizados.
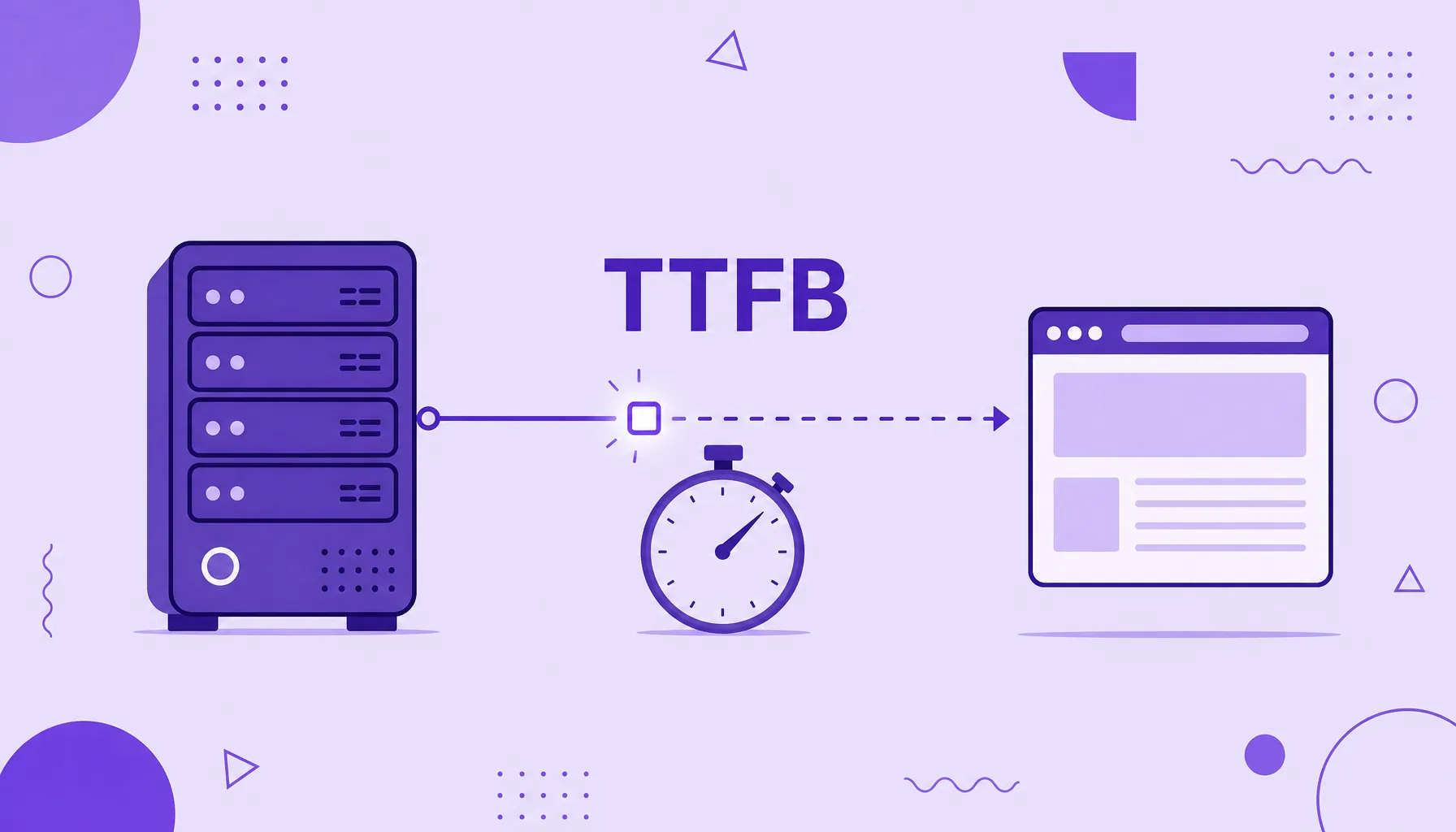
Time to First Byte
Time to First Byte (TTFB), o tiempo hasta el primer byte, es el tiempo que el navegador espera desde que pide una página hasta que recibe el primer byte de la respuesta del servidor. Es un indicador de la velocidad del backend, es decir, de qué tan rápido el servidor procesa y empieza a responder a la petición. Un TTFB alto retrasa todo lo demás de la carga y suele ser el primer cuello de botella a resolver en rendimiento web.
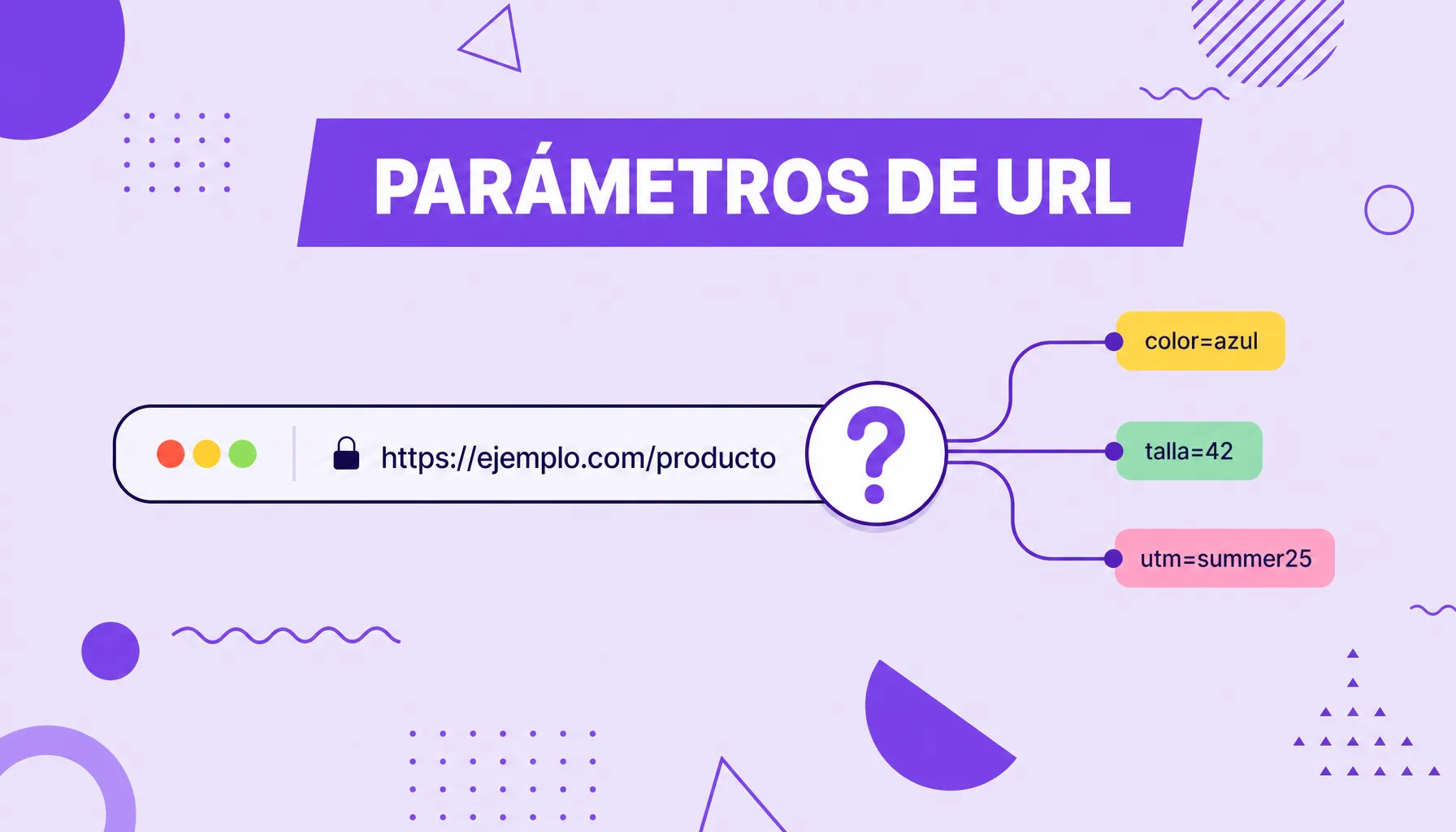
Parámetros de URL
Los parámetros de URL son fragmentos añadidos al final de una dirección, después de un signo de interrogación, que envían información extra al servidor, como filtros de producto, términos de búsqueda interna, identificadores de sesión o marcadores de campaña (UTMs). Son útiles para rastrear tráfico y organizar páginas dinámicas, pero, cuando se controlan mal, pueden generar contenido duplicado, desperdiciar el rastreo del buscador y diluir las señales de posicionamiento de una página.

Redirección 302
La redirección 302 es un código de estado HTTP que informa al navegador y a los buscadores que una página se movió de forma temporal a otra URL. A diferencia del 301, que es permanente, el 302 señala que la dirección original volverá a funcionar, por eso Google mantiene la URL antigua indexada y no traspasa la autoridad de forma definitiva a la nueva dirección. Es el desvío indicado para situaciones pasajeras, como pruebas, mantenimientos y promociones.

Cadena de redirecciones
Una cadena de redirecciones es una secuencia en la que una URL redirige a otra, que a su vez redirige a una tercera, y así sucesivamente, antes de llegar al destino final. Cada salto extra suma tiempo de carga, gasta presupuesto de rastreo y diluye la autoridad transferida por los enlaces. Lo ideal es que cualquier URL redirija una sola vez, directo a la dirección final, sin pasos intermedios.

SEO para JavaScript
El SEO para JavaScript es el conjunto de prácticas que garantiza que los sitios construidos con JavaScript sean rastreados, renderizados e indexados correctamente por los buscadores. Como el contenido en JS muchas veces solo aparece después de que el navegador ejecuta el código, Google necesita un paso extra de renderizado para ver la página. Optimizar para JavaScript es hacer ese contenido accesible al buscador, sin depender solo de lo que el robot ve en el HTML inicial.

Schema.org
Schema.org es el vocabulario estandarizado de datos estructurados creado en conjunto por Google, Microsoft, Yahoo y Yandex para describir el contenido de las páginas de forma que las máquinas lo entiendan. Define tipos (como Producto, Artículo, Evento) y propiedades (como nombre, precio, autor) que los buscadores reconocen. No es un código que instalas, sino el diccionario compartido que usas al marcar una página con datos estructurados.

Cabecera X-Robots-Tag
La cabecera X-Robots-Tag es una directiva de indexación enviada en la respuesta HTTP del servidor, y no en el HTML de la página. Cumple el mismo papel que la meta etiqueta robots (decirle al buscador que no indexe, que no siga enlaces o que no archive una URL), pero con una ventaja decisiva: funciona para cualquier tipo de archivo, incluidos PDF, imágenes y hojas de cálculo, donde no existe un head HTML para recibir la meta etiqueta.