Qué es la cabecera X-Robots-Tag y cómo controlar la indexación
Por Tiago CostaActualizado el 2 de julio de 2026

La X-Robots-Tag es una cabecera HTTP que controla cómo el buscador indexa una URL. En la práctica:
- viaja en la respuesta del servidor, fuera del HTML de la página;
- acepta las mismas directivas que la meta robots, como noindex y nofollow;
- es la única forma de aplicar noindex en PDF, imágenes y otros archivos no HTML;
- permite aplicar reglas en masa por tipo de archivo en el servidor.
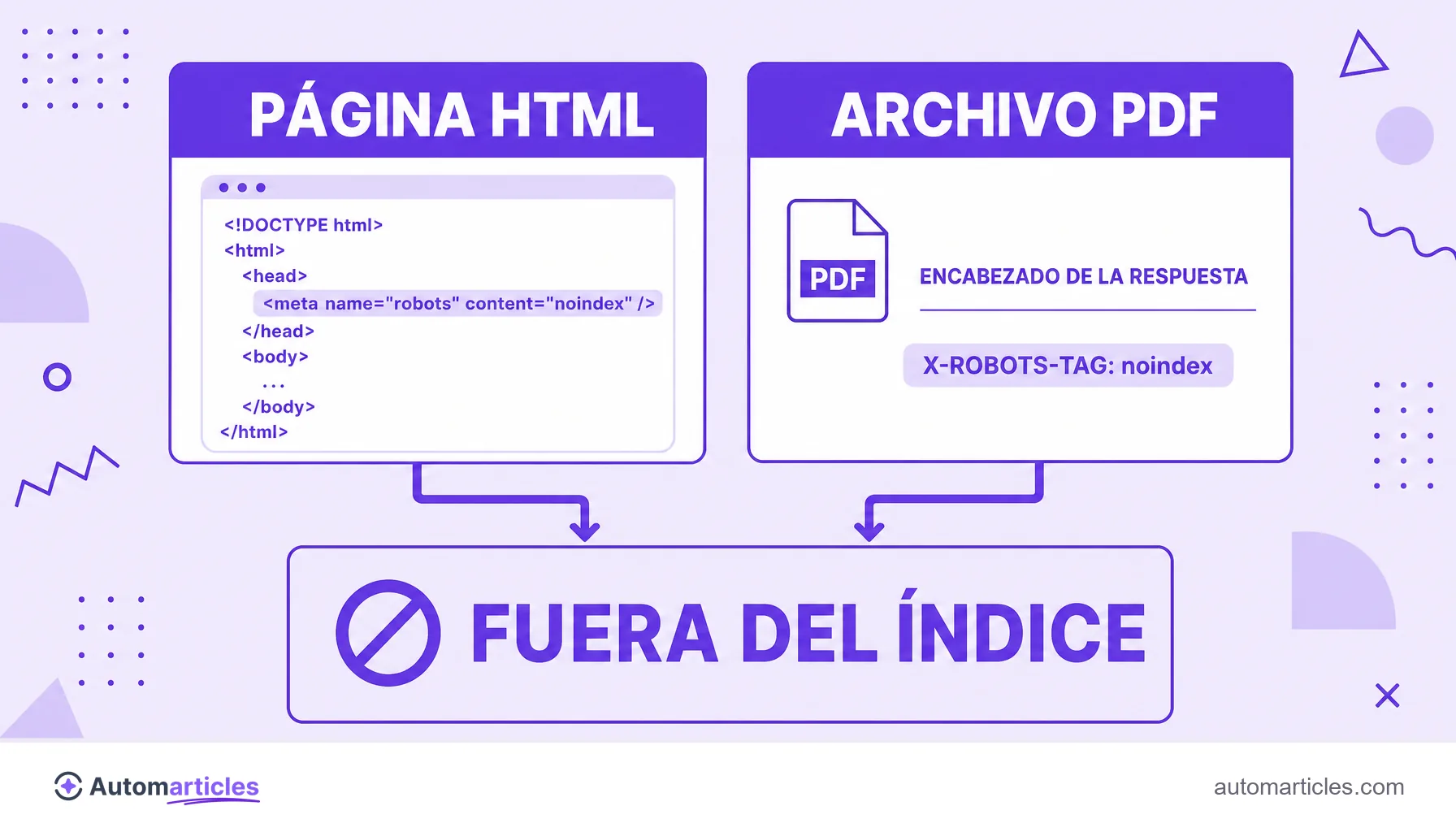
Qué es la cabecera X-Robots-Tag
La X-Robots-Tag es una cabecera HTTP, es decir, una línea de información que el servidor envía junto con la respuesta de una URL, incluso antes del contenido en sí. En esa cabecera puedes incluir directivas de indexación que indican a los buscadores cómo tratar esa página o archivo: si se puede indexar, si debe seguir los enlaces, si puede mostrar una versión en caché y así sucesivamente.
La diferencia central respecto a la conocida meta etiqueta robots es dónde vive la instrucción. La meta etiqueta está dentro del HTML, en la sección head de la página. En cambio, la X-Robots-Tag está en la respuesta del servidor, en un nivel anterior al contenido. Las dos consiguen el mismo efecto sobre la indexación, pero por caminos diferentes.
Esta distinción no es un detalle técnico sin importancia. Resuelve un problema real: cómo impedir la indexación de archivos que no tienen HTML, como un PDF o una imagen. Sin una sección head para recibir una meta etiqueta, esos archivos solo se pueden controlar con la cabecera HTTP.
X-Robots-Tag frente a la meta robots: cuándo usar cada una
Las dos herramientas entregan las mismas directivas, así que la elección depende de lo que necesitas controlar y de dónde es más práctico aplicar la regla:
- Meta etiqueta robots: ideal para páginas HTML individuales. Basta con insertar la línea <meta name="robots" content="noindex"> en el head del documento. Es simple y no exige acceso al servidor.
- X-Robots-Tag: ideal para archivos no HTML (PDF, imágenes, vídeos) y para aplicar reglas en masa. Como está en el servidor, puedes, por ejemplo, enviar noindex a todos los PDF de una carpeta de una sola vez.
Conviene reforzar una regla que confunde a mucha gente: tanto la meta etiqueta como la X-Robots-Tag solo funcionan si el buscador consigue rastrear la URL y leer la instrucción. Si bloqueas la misma página en robots.txt, el robot nunca llega a ver la cabecera, y la directiva de noindex se ignora. El bloqueo de rastreo y una directiva de indexación son cosas distintas que no deben combinarse en la misma URL.
Qué valores acepta la X-Robots-Tag
La X-Robots-Tag reconoce las mismas directivas que la meta etiqueta robots, y puedes combinar más de una, separadas por coma. Las más usadas:
| Valor | Qué le dice al buscador |
|---|---|
| noindex | No incluir esta URL en los resultados de búsqueda. |
| nofollow | No seguir los enlaces contenidos en ese recurso. |
| none | Atajo para noindex y nofollow juntos. |
| noarchive | No mostrar una versión en caché del recurso. |
| nosnippet | No mostrar fragmento de texto ni vista previa en el resultado. |
| unavailable_after | Dejar de indexar la URL después de una fecha definida. |
También es posible dirigir la directiva a un robot específico, nombrando el agente antes del valor (por ejemplo, aplicar la regla solo a Googlebot). Esa flexibilidad hace de la X-Robots-Tag una herramienta poderosa para quien gestiona muchos tipos de archivo diferentes.
Cómo configurar la X-Robots-Tag en el servidor
Como la X-Robots-Tag vive en la respuesta HTTP, la configuración se hace en el servidor web, no en el contenido. Los caminos más comunes:
- Apache: en el archivo de configuración o en el .htaccess, una regla del tipo Header set X-Robots-Tag "noindex" puede combinarse con un filtro por extensión para alcanzar solo los PDF, por ejemplo.
- Nginx: dentro del bloque del servidor, la directiva add_header X-Robots-Tag "noindex"; aplica la regla a las URLs que especifiques.
- WordPress: los plugins de SEO permiten marcar tipos de contenido con noindex, y algunos ya se encargan de la cabecera para archivos de medios sin que toques el servidor.
El punto de atención es siempre el mismo: aplicar la regla al objetivo correcto. Un filtro mal configurado puede acabar enviando noindex a páginas importantes, así que cada cambio pide una prueba antes de ir a producción. Equivocarse aquí hunde páginas enteras de la búsqueda sin aviso.
Casos de uso: PDF, imágenes y archivos no HTML
Es en los archivos que no son páginas HTML donde la X-Robots-Tag brilla, porque en ellos la meta etiqueta simplemente no existe. Situaciones típicas:
- PDF internos: catálogos, manuales y materiales que no quieres que compitan en los resultados con las páginas del sitio.
- Imágenes sensibles: archivos que deben quedar accesibles para quien tiene el enlace, pero fuera de la búsqueda de imágenes.
- Hojas de cálculo y documentos: exportaciones e informes que generan contenido duplicado o de bajo valor para la búsqueda.
- Áreas de descarga: carpetas enteras que tienen más sentido fuera del índice.
Conviene recordar que estas directivas forman parte de un universo bien consolidado. Según el estudio del Web Almanac de HTTP Archive, en 2024 la directiva noindex estaba presente en cerca del 4,7% de las páginas en escritorio y el 3,9% en móviles, señal de que el control de indexación, ya sea por meta etiqueta o por cabecera, es una práctica común en la web. Para complementar, el texto alternativo sigue siendo el camino para describir imágenes que sí quieres indexar.

Cómo verificar y evitar errores con la X-Robots-Tag
Como la cabecera no aparece en el HTML visible, es fácil aplicarla sin querer u olvidar quitarla. Una rutina para comprobar que todo está bien:
- Inspecciona las cabeceras HTTP: las herramientas de desarrollador del navegador o los verificadores de cabecera muestran si la X-Robots-Tag está presente y con qué valor.
- Garantiza que la URL es rastreable: confirma que no está bloqueada en robots.txt, si no, el buscador no leerá la directiva.
- Usa la inspección de URL: la herramienta de inspección de URL de Search Console indica si Google ve la página como excluida por una directiva noindex.
- Comprueba el código de estado: un código de estado HTTP correcto, junto con la cabecera adecuada, evita señales contradictorias para el robot.
El error más caro de la X-Robots-Tag es el silencioso: un noindex olvidado en una regla amplia del servidor puede desindexar secciones enteras sin que nadie lo note de inmediato. Revisar las cabeceras tras cualquier cambio de infraestructura es la mejor forma de prevención.