SEO para JavaScript: qué es y cómo funciona
Por Tiago CostaActualizado el 2 de julio de 2026

El SEO para JavaScript es la optimización de sitios en JS para que los buscadores puedan leer e indexar el contenido. En la práctica:
- garantiza que el contenido aparezca aunque dependa de JavaScript;
- tiene en cuenta el paso extra de renderizado que Google hace en estos sitios;
- evita que texto, enlaces y metadatos queden invisibles para el robot;
- usa renderizado en el servidor o prerrenderizado para acelerar la indexación.
Qué es el SEO para JavaScript
El SEO para JavaScript es el área del SEO técnico que se ocupa de sitios hechos con frameworks y librerías de JavaScript, como React, Vue y Angular, para que el contenido generado por ese código sea comprendido por los motores de búsqueda. El reto es fácil de enunciar y difícil de resolver: buena parte de lo que el usuario ve en estas páginas no existe en el HTML que entrega el servidor, sino que se monta después, en el navegador, cuando el JavaScript se ejecuta.
Un sitio tradicional entrega una página lista en HTML. El robot del buscador la abre y lee el texto, los enlaces y los metadatos de inmediato. En cambio, un sitio que depende de JS puede entregar un HTML casi vacío, con el contenido real inyectado solo después por la ejecución del código. Si el buscador no consigue ejecutar ese JavaScript, ve una página en blanco.
Por eso el SEO para JavaScript es una disciplina dentro del SEO técnico: conecta decisiones de desarrollo (cómo se construye el sitio) con el objetivo de negocio (aparecer en la búsqueda). La buena noticia es que, con las prácticas correctas, un sitio en JavaScript puede posicionar tan bien como cualquier otro.
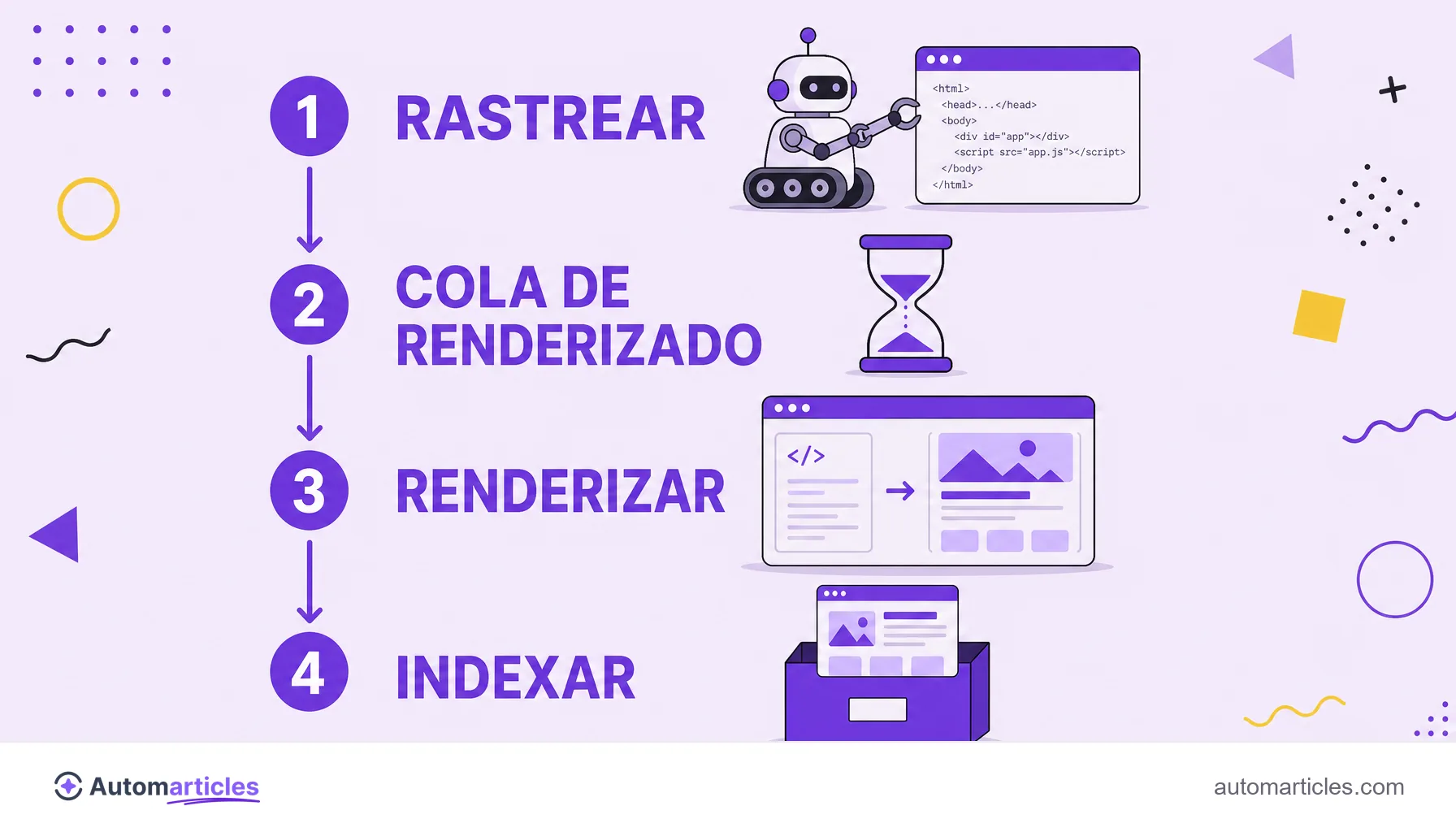
Cómo Google rastrea y renderiza JavaScript
Para entender el SEO para JavaScript hay que separar tres procesos que, en un sitio en HTML puro, ocurren casi juntos, pero en un sitio en JS quedan muy separados:
- Rastreo: el crawler de Google descarga el HTML inicial de la URL.
- Renderizado: la página entra en una cola y, cuando hay recursos disponibles, Google ejecuta el JavaScript en un navegador headless para montar el contenido final.
- Indexación: solo después de renderizar, el buscador guarda el contenido en el índice y lo considera para la indexación.
El paso de renderizado es lo que cambia todo. No es instantáneo ni garantizado: la página queda en una cola que puede tardar de segundos a días. Y aquí está el coste oculto del JavaScript. Según un estudio de Onely, Googlebot necesita cerca de 9 veces más tiempo para procesar contenido en JavaScript que el mismo contenido en HTML, lo que retrasa la entrada de la página en la búsqueda.
Por qué el JavaScript puede perjudicar el SEO
JavaScript no es enemigo del SEO, pero el uso descuidado crea trampas que hunden el rendimiento de un sitio en la búsqueda. Los problemas más comunes son:
- Contenido invisible en el HTML inicial: si el texto y los títulos solo aparecen tras ejecutar el JS, el buscador puede indexar una página vacía mientras no la renderiza.
- Enlaces que el robot no sigue: la navegación construida con eventos de clic en lugar de etiquetas de ancla con atributo href impide al crawler descubrir páginas internas.
- Metadatos dinámicos tardíos: el title y la meta description definidos solo vía JavaScript pueden no leerse a tiempo, perjudicando el snippet en la SERP.
- Desperdicio de rastreo: los archivos JS pesados y las llamadas a API consumen el presupuesto de rastreo, reduciendo cuántas páginas visita Google.
- Errores de ejecución: un script que falla en el navegador de Google puede dejar toda la página sin contenido, aunque funcione en tu navegador.
El hilo conductor de todos estos problemas es el mismo: cuanto más depende el contenido esencial del JavaScript para existir, más frágil se vuelve la indexación. La solución pasa por decidir dónde se ejecuta ese código.
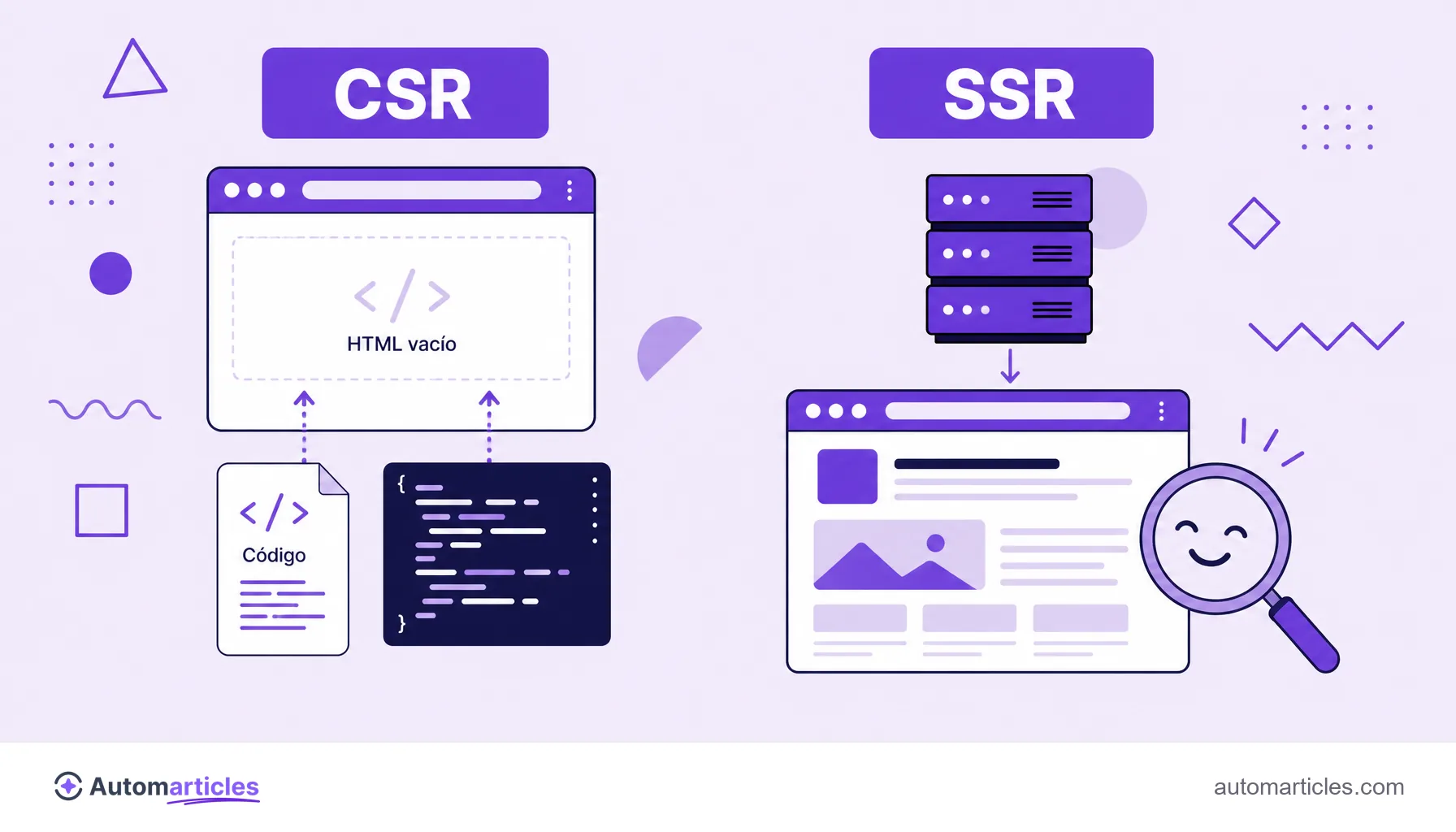
Renderizado: CSR, SSR, SSG y prerrenderizado
Elegir dónde se ejecuta el JavaScript (en el navegador del usuario o en el servidor) es la decisión más importante del SEO para JavaScript. Las principales estrategias son:
| Estrategia | Dónde se monta el contenido | Impacto en el SEO |
|---|---|---|
| CSR (client-side rendering) | En el navegador del usuario, tras descargar el JS. | Más frágil, depende del renderizado de Google. |
| SSR (server-side rendering) | En el servidor, que entrega el HTML ya listo. | Óptimo, el contenido llega visible al robot. |
| SSG (static site generation) | En la build, generando páginas estáticas. | Excelente, rápido y totalmente indexable. |
| Prerrenderizado | Una versión estática servida a los bots. | Buen paliativo cuando no se puede migrar. |
La regla práctica es directa: cuanto más cerca del servidor se monta el contenido, menos dependes de la cola de renderizado de Google y más fiable es la indexación. Frameworks modernos como Next.js y Nuxt nacieron justamente para ofrecer SSR y SSG con poco esfuerzo, lo que los convierte en aliados naturales de quien se preocupa por la búsqueda.
Buenas prácticas de SEO para JavaScript
Después de elegir la estrategia de renderizado, un conjunto de cuidados garantiza que el sitio en JavaScript sea amigable para la búsqueda:
- Entrega el contenido crítico en el HTML: el texto principal, los títulos y los enlaces importantes deben existir ya en la respuesta del servidor, no solo tras ejecutar el JS.
- Usa enlaces de verdad: navegación con etiquetas de ancla y atributo href, para que el robot descubra y siga tus páginas.
- Define los metadatos en el servidor: el title, la meta description y las meta tags deben llegar listos, sin depender de scripts tardíos.
- Cuida el rendimiento: el JavaScript pesado empeora los Core Web Vitals, así que divide el código, aplaza lo que no es esencial y optimiza la carga.
- No bloquees los archivos JS: deja que el buscador acceda a tus scripts y CSS en robots.txt, si no, no puede renderizar la página.
- Mantén un sitemap actualizado: un sitemap XML ayuda a Google a descubrir URLs que la navegación en JS podría esconder.
Ninguna de estas prácticas exige abandonar el JavaScript. Solo garantizan que el contenido esencial no quede rehén de un paso de renderizado que puede retrasarse o fallar.
Cómo probar y diagnosticar el SEO de un sitio en JavaScript
No tienes que adivinar cómo ve Google un sitio en JavaScript, se puede comprobar en la práctica. Una rutina de diagnóstico:
- Compara el HTML y el contenido renderizado: mira el código fuente crudo (sin ejecutar JS) y compáralo con la página final. Lo que aparece solo en la versión renderizada es lo que está en riesgo.
- Usa la inspección de URL: la herramienta de inspección de URL de Search Console muestra el HTML renderizado que Google realmente ve, con una captura de la página.
- Prueba el renderizado en vivo: las herramientas de prueba de compatibilidad con móviles muestran cómo el robot procesa el JavaScript de la URL.
- Busca fragmentos de texto en Google: buscar una frase exacta de la página entre comillas revela si ese contenido fue de hecho indexado.
- Sigue la cobertura: en Google Search Console, el informe de indexación señala páginas descubiertas pero no indexadas, un síntoma clásico de un problema con JavaScript.
Diagnosticar temprano evita la peor sorpresa del SEO para JavaScript: descubrir, meses después, que páginas enteras nunca entraron en el índice porque el buscador no consiguió renderizarlas.