TF-IDF: what it is and how it works in SEO
By Tiago CostaUpdated on July 2, 2026

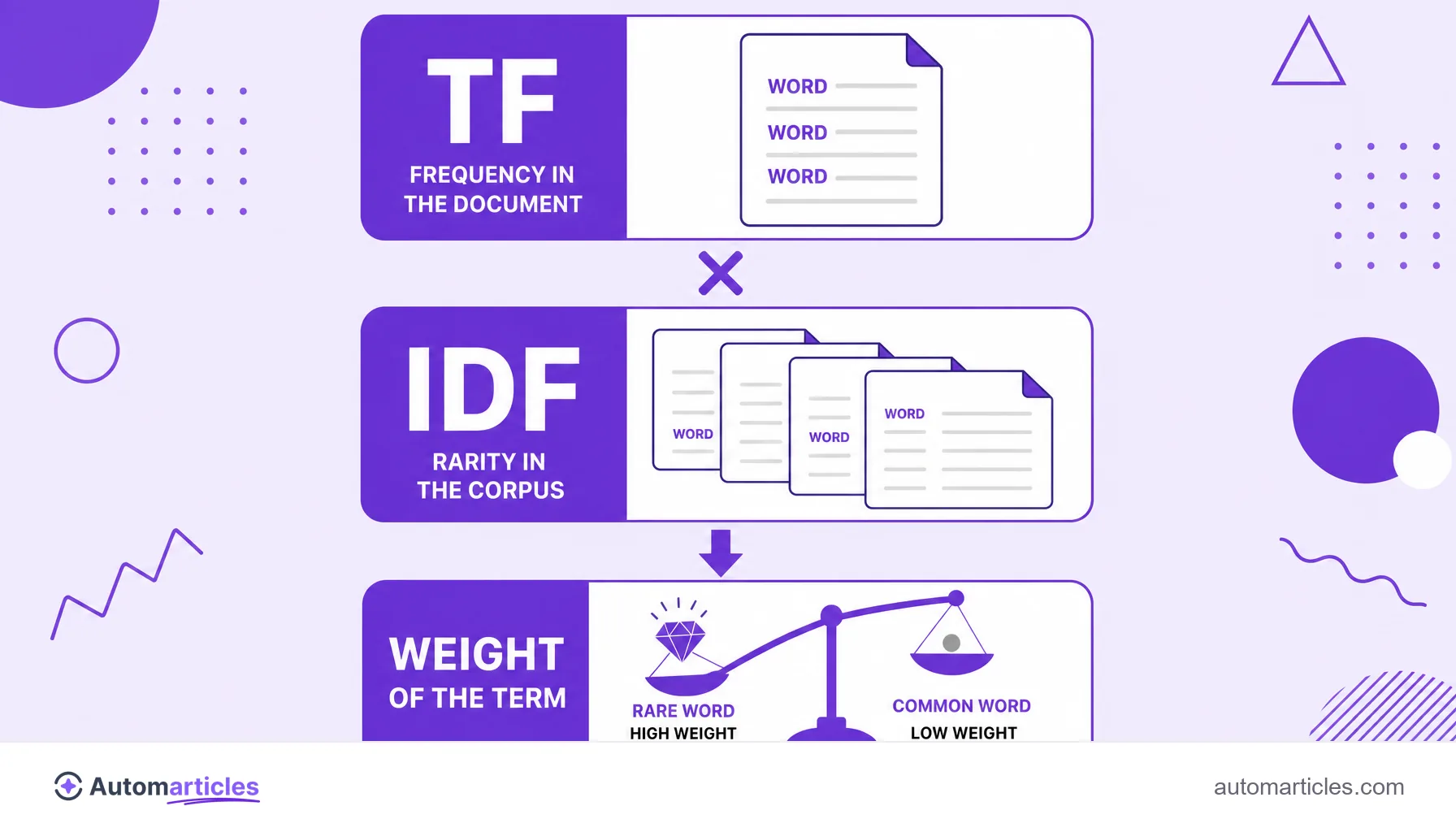
TF-IDF combines two measures to calculate the weight of a word in a text:
- TF (Term Frequency): how many times the term appears in the document;
- IDF (Inverse Document Frequency): how rare the term is across the whole corpus.
Multiplying the two, words that are frequent on the page and rare on the web get a high weight, while common words like "the" and "for" get a low weight.
What TF-IDF is and what the acronym means
TF-IDF stands for Term Frequency, Inverse Document Frequency. It is a classic statistical measure from information retrieval, created to answer a simple question: within a text, which words really matter to describe the subject?
The intuition is easy to grasp. If the word photosynthesis appears several times in an article and barely shows up in the other texts of the collection, it is a great clue to that article's topic. Words like of, that and for, on the other hand, appear in almost everything, so they do not help tell one document from another and get a low weight.
That is why TF-IDF became the backbone of old search engines, spam filters and recommendation systems. It turns text into numbers that can be compared, the first step for a machine to understand what a keyword is talking about.
How the TF-IDF formula works
TF-IDF is the product of two components calculated separately and then multiplied.
TF (Term Frequency) measures how often the term appears in the document. In its most common form, it is the number of times the word appears divided by the total number of words in the text, so short documents are not penalized nor long ones inflated.
IDF (Inverse Document Frequency) measures how rare the term is across the corpus. It is the logarithm of the total number of documents divided by the number of documents that contain that term. The rarer the term, the higher the IDF; the more common, the closer the IDF gets to zero.
The final result is TF x IDF. A word only reaches a high weight when it is frequent in that text and uncommon in the set. If it is frequent everywhere, the IDF pulls the value down. If it is rare in the collection but does not even appear in the document, the TF zeroes out the calculation.
TF-IDF in practice: a step by step example
Imagine a corpus of 1,000 articles from a blog. You want to know the weight of the words in a post about specialty coffee. Look at three terms from that post:
| Term | Appearances in the post | Documents with the term | Relative weight |
|---|---|---|---|
| of | 40 | 1,000 | Low |
| coffee | 18 | 300 | Medium |
| roast | 9 | 25 | High |
The word of appears a lot, but it is in all 1,000 documents, so the IDF drives it close to zero. Coffee is relevant, yet it shows up across much of the blog, which lowers its weight. Roast, present in only 25 texts, earns the highest relative weight: it is the word that best characterizes that specific post.
This reasoning explains why stuffing the text with the main term does not work. Repeating the target word raises the TF, but does not change the IDF, and it runs into keyword stuffing, the artificial repetition of words. What enriches the content is the natural presence of supporting terms, the ones that add depth to the topic.
TF-IDF in SEO: what it is really for
An important warning: TF-IDF is not a direct ranking factor for Google. Google itself has downplayed its weight. In statements compiled by Search Engine Journal, John Mueller described TF-IDF as a very old metric and said it is not even fully calculable, since it would depend on statistics of the entire web. The modern search engine uses language models and far more sophisticated signals.
Even so, the reasoning behind TF-IDF is still useful as an analysis tool. It helps map the vocabulary that the content already ranking uses to cover a topic, revealing supporting terms that might be missing from your text. It is a support for semantic SEO, not a goal in itself.
In practice, content optimization tools use variations of TF-IDF to suggest related words. The mistake is treating the list as a target to hit. The healthy use is as a coverage checklist: if the topic calls for subtopics you forgot, TF-IDF turns on the light.
TF-IDF, keyword density and LSI: what is different
These three concepts are easy to mix up, but they measure different things.
- TF-IDF: weighs a term in the document against a whole corpus. It is relative and takes the rest of the collection into account.
- Keyword density: keyword density is just the percentage of times a term appears in a text, with no comparison to anything external.
- LSI: the concept of LSI (latent semantic indexing) tries to uncover meaning relationships between terms, going beyond simple counting.
At the scale and language of the real web, none of these calculations is done in the pure form the textbooks describe. They work better as mental models: TF-IDF reminds you that relevance is relative, density warns against overdoing it, and LSI reinforces the idea of covering a topic by meaning, not by repetition.

How to use TF-IDF thinking in your content
You do not need to calculate logarithms to benefit from the idea. A practical script:
- Study who already ranks: list the recurring supporting terms in the top texts and see what is missing from yours.
- Cover the topic, not the word: instead of repeating the target term, bring variations, synonyms and subtopics the subject calls for.
- Avoid overdoing it: repeating the main word does not raise perceived relevance and may look like spam.
- Write for people: a text that answers the question well usually includes the right terms naturally.
- Use tools as support, not as a rule: lists of suggested terms help you remember gaps, but the final criterion is clarity for the reader.
In the end, TF-IDF is more valuable as a way of thinking than as a number to chase. Covering a subject with depth and rich vocabulary is what the search engine rewards, with or without the formula in hand.