SEO tecnico e SERP
A parte tecnica do site e os recursos da pagina de resultados.
Google Search Console
O Google Search Console (GSC) é uma ferramenta gratuita do Google que mostra como o buscador enxerga o seu site. Nela você acompanha quais páginas estão indexadas, quantos cliques e impressões cada conteúdo recebe na busca, em quais palavras-chave você aparece e quais problemas técnicos podem estar atrapalhando o seu desempenho nos resultados orgânicos.

LCP
LCP, sigla de Largest Contentful Paint (maior renderização de conteúdo), é uma das métricas dos Core Web Vitals do Google. Ela mede quanto tempo o maior elemento visível da página, geralmente uma imagem de destaque ou um bloco de texto grande, leva para aparecer na tela desde o início do carregamento. Quanto menor o LCP, mais rápido o usuário sente que a página carregou.

AMP
AMP é a sigla de Accelerated Mobile Pages, ou páginas móveis aceleradas, um formato aberto criado pelo Google em 2015 para fazer páginas web carregarem quase instantaneamente no celular. Na prática, o AMP é uma versão enxuta de uma página, escrita com regras rígidas de HTML e JavaScript para pesar menos e renderizar mais rápido, o que já foi decisivo para notícias e artigos no mobile.

Erro 404
O erro 404 é o código de status HTTP que o servidor devolve quando a página pedida não é encontrada no endereço acessado. Ele indica que a URL não existe (ou não existe mais), seja porque foi digitada errada, removida ou teve o endereço alterado. Sozinho, o 404 é um comportamento normal da web, mas em excesso e em páginas importantes ele prejudica a experiência do usuário e o SEO.

Erro 500
O erro 500, ou Internal Server Error, é um código de status HTTP que indica uma falha interna e inesperada no servidor, algo que o impede de entregar a página solicitada. Diferente de um erro 404, que aponta uma página inexistente, o 500 mostra que o endereço existe, mas alguma coisa no servidor quebrou no meio do caminho. É um erro genérico, ou seja, sinaliza o problema sem detalhar a causa exata.

INP
O INP, sigla de Interaction to Next Paint (interação até a próxima renderização), é uma das métricas dos Core Web Vitals do Google. Ele mede a responsividade da página, ou seja, quanto tempo ela leva para responder visualmente depois que o usuário clica, toca ou digita. Quanto menor o INP, mais rápida e fluida é a experiência. O INP substituiu o antigo FID (First Input Delay) como métrica oficial de responsividade.

CLS
CLS, sigla de Cumulative Layout Shift (mudança cumulativa de layout), é a métrica dos Core Web Vitals do Google que mede a estabilidade visual de uma página enquanto ela carrega. Ele quantifica o quanto os elementos saltam de posição de forma inesperada, aquele incômodo de tentar clicar em um botão e ver a página pular. Quanto menor o CLS, mais estável e agradável é a experiência.
Crawler
Crawler é um programa robô que percorre a web de link em link, baixando e lendo páginas para alimentar o índice de um buscador. Também chamado de spider, robô ou bot, o exemplo mais conhecido é o Googlebot. O crawler é a primeira etapa da busca: antes de uma página poder ser indexada e ranqueada, ela precisa ser encontrada e lida por um desses rastreadores.
Sitemap XML
Sitemap XML é um arquivo em formato XML que lista as URLs importantes de um site para ajudar os buscadores a descobrir, rastrear e priorizar essas páginas. Ele funciona como um mapa do site entregue ao Google, informando quais endereços existem e, opcionalmente, quando foram atualizados, o que é especialmente útil em sites grandes, novos ou com páginas pouco conectadas por links internos.
JSON-LD
JSON-LD (JavaScript Object Notation for Linked Data) é o formato recomendado pelo Google para inserir dados estruturados em uma página, dentro de um bloco de script separado do conteúdo visível. Em vez de espalhar marcações no meio do HTML, ele reúne tudo em um objeto JSON com o vocabulário do Schema.org, dizendo ao buscador de forma explícita o que cada informação representa (um autor, um preço, uma avaliação, uma data) para habilitar resultados ricos na busca.

Erro 410
O erro 410, ou 410 Gone, é o código de status HTTP que informa que uma página foi removida de forma permanente e não vai voltar. Diferente do 404, que apenas diz que a página não foi encontrada agora, o 410 é um sinal explícito de remoção definitiva. Por ser mais categórico, ele tende a acelerar a desindexação do endereço nos buscadores, sendo útil quando você quer tirar de vez um conteúdo do índice do Google.
Hreflang
Hreflang é um atributo HTML que informa aos buscadores o idioma e, opcionalmente, a região de uma página, para que eles mostrem a versão certa a cada usuário. Em sites com conteúdo em vários idiomas ou voltado a países diferentes, as tags hreflang conectam as versões equivalentes de uma mesma página e evitam que elas concorram entre si ou apareçam para o público errado. É uma peça central do SEO internacional.

Código de status HTTP
Um código de status HTTP é o número de três dígitos que o servidor devolve a cada requisição feita por um navegador ou por um robô de busca, informando o resultado daquele pedido. Ele é organizado em cinco classes: 1xx (informativo), 2xx (sucesso, como o 200), 3xx (redirecionamento, como o 301), 4xx (erro do cliente, como o 404) e 5xx (erro do servidor, como o 500). Em SEO, esses códigos dizem aos buscadores se a página pode ser indexada, se foi movida ou se saiu do ar.

Inspeção de URL
A inspeção de URL é a ferramenta do Google Search Console que mostra, para qualquer página do seu site, se ela está indexada, como o Google a rastreou, qual URL foi escolhida como canônica e se há problemas que impedem a página de aparecer na busca. É o exame de diagnóstico página a página, usado tanto para conferir o status atual quanto para pedir a indexação de conteúdos novos ou atualizados.

Time to First Byte
Time to First Byte (TTFB), ou tempo até o primeiro byte, é o tempo que o navegador espera desde que pede uma página até receber o primeiro byte da resposta do servidor. É um indicador da velocidade do backend, ou seja, de quão rápido o servidor processa e começa a responder à requisição. Um TTFB alto atrasa todo o resto do carregamento e costuma ser o primeiro gargalo a resolver em performance web.

Parâmetros de URL
Parâmetros de URL são trechos adicionados ao final de um endereço, depois de um ponto de interrogação, que enviam informações extras ao servidor, como filtros de produto, termos de busca interna, identificadores de sessão ou marcadores de campanha (UTMs). Eles são úteis para rastrear tráfego e organizar páginas dinâmicas, mas, quando mal controlados, podem gerar conteúdo duplicado, desperdiçar o rastreamento do buscador e diluir os sinais de ranqueamento de uma página.

Redirecionamento 302
O redirecionamento 302 é um código de status HTTP que informa ao navegador e aos buscadores que uma página foi movida de forma temporária para outra URL. Diferente do 301, que é permanente, o 302 sinaliza que o endereço original vai voltar a funcionar, por isso o Google mantém a URL antiga indexada e não repassa em definitivo a autoridade para o novo endereço. É o desvio indicado para situações passageiras, como testes, manutenções e promoções.

Cadeia de redirecionamentos
Cadeia de redirecionamentos é uma sequência em que uma URL redireciona para outra, que por sua vez redireciona para uma terceira, e assim por diante, antes de chegar ao destino final. Cada salto extra soma tempo de carregamento, gasta orçamento de rastreamento e dilui a autoridade transferida pelos links. O ideal é que qualquer URL redirecione uma única vez, direto para o endereço final, sem passos intermediários.

SEO para javascript
SEO para JavaScript é o conjunto de práticas que garante que sites construídos com JavaScript sejam rastreados, renderizados e indexados corretamente pelos buscadores. Como o conteúdo em JS muitas vezes só aparece depois que o navegador executa o código, o Google precisa de uma etapa extra de renderização para enxergar a página. Otimizar para JavaScript é fazer esse conteúdo ficar acessível ao buscador, sem depender apenas do que o robô vê no HTML inicial.

Schema.org
Schema.org é o vocabulário padronizado de dados estruturados criado em conjunto por Google, Microsoft, Yahoo e Yandex para descrever o conteúdo das páginas de forma que as máquinas entendam. Ele define tipos (como Produto, Artigo, Evento) e propriedades (como nome, preço, autor) que os buscadores reconhecem. Não é um código que você instala, e sim o dicionário compartilhado que você usa ao marcar uma página com dados estruturados.
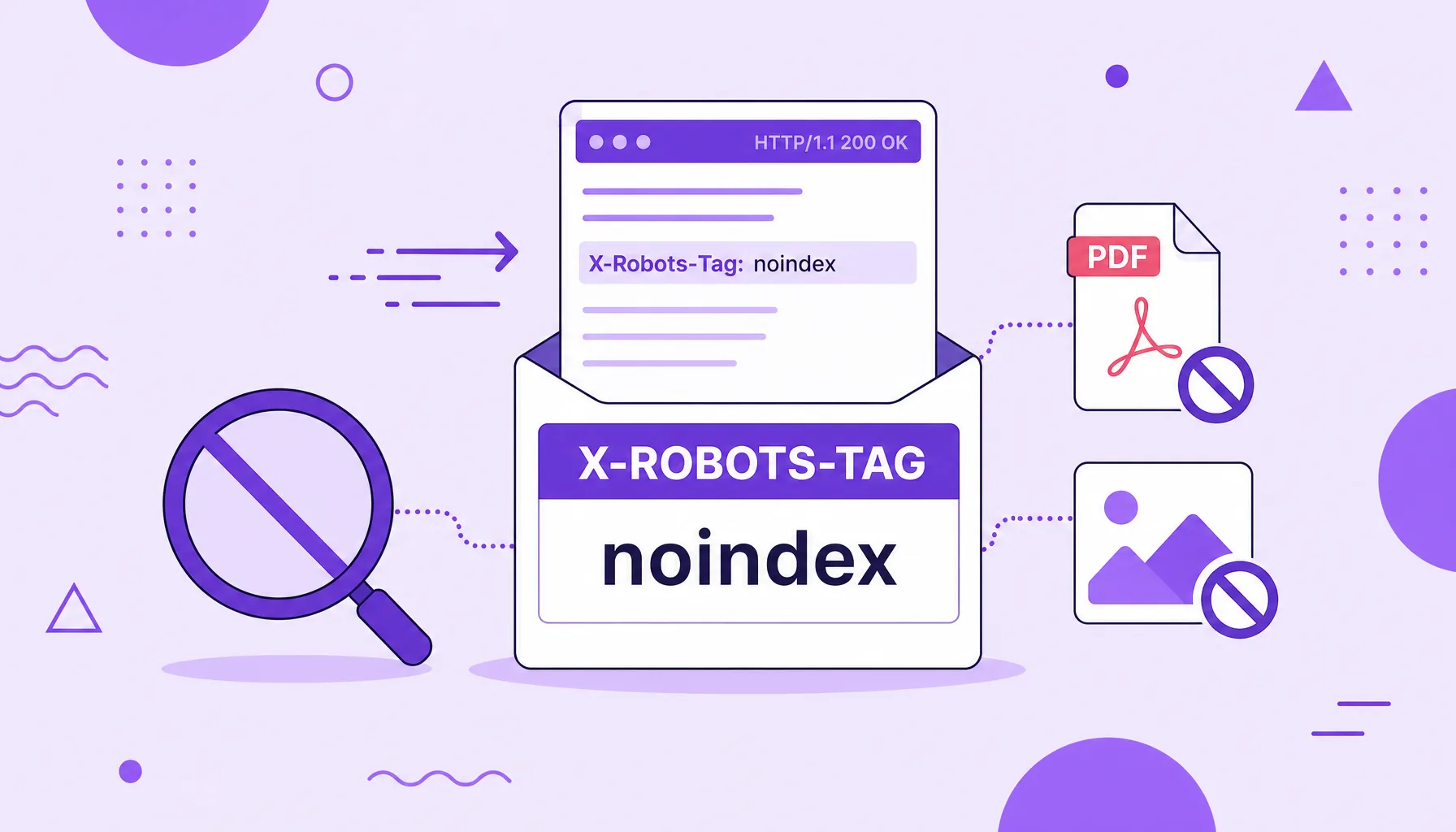
Cabeçalho x-robots-tag
O cabeçalho X-Robots-Tag é uma diretiva de indexação enviada na resposta HTTP do servidor, e não no HTML da página. Ele cumpre o mesmo papel da meta tag robots (dizer ao buscador para não indexar, não seguir links ou não arquivar uma URL), mas com uma vantagem decisiva: funciona para qualquer tipo de arquivo, inclusive PDFs, imagens e planilhas, onde não existe um cabeçalho HTML para receber a meta tag.