What a crawler (web crawler) is and how it works in SEO
By Tiago CostaUpdated on July 2, 2026
A crawler (or web crawler) is the bot that search engines use to discover and read the pages of the web. In practice, a crawler:
- starts from a list of known URLs and visits each page;
- reads the content and follows the links to find new pages;
- sends what it finds to the search engine index;
- respects instructions such as robots.txt and the noindex tag.
What a crawler is and how it works
A crawler is an automated program that browses the web systematically, jumping from link to link to discover and read pages. It goes by several names that mean the same thing: web crawler, spider, robot or bot. The most famous of all is Googlebot, the crawler of Google's search engine.
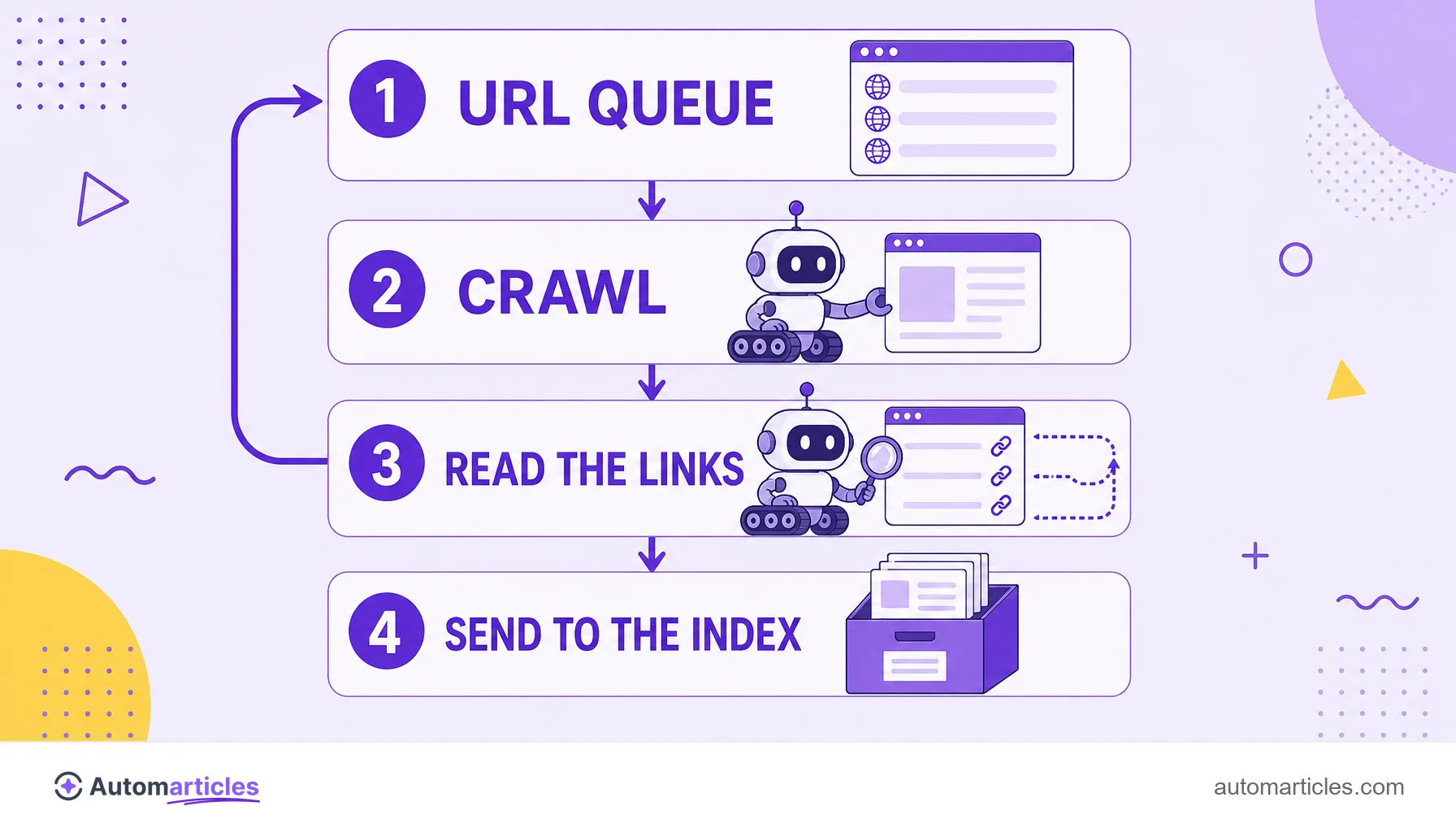
The process is a simple cycle that repeats on a giant scale. The crawler starts with a list of URLs it already knows, visits each one, reads the page HTML, extracts all the links found and adds the new addresses to a queue to visit later. So, page after page, it maps the entire web.
The scale of this work is hard to picture. According to Google's documentation on how Search works, the index fed by these crawlers already covers hundreds of billions of pages and takes up well over 100 million gigabytes. All of it starts with the simplest step: a bot visiting an address.
Crawling, indexing and ranking: where the crawler fits
It is common to confuse the crawler's job with the whole search engine, but it is only the first of three stages. Understanding this split avoids a lot of SEO mistakes:
- Crawling: the crawler finds and downloads the page. This is where the bot comes in.
- Indexing: the search engine analyzes the downloaded content and stores it in the index. See the indexing process in detail.
- Ranking: when someone searches, the search engine orders the already indexed pages by relevance.
The practical consequence matters: being crawled does not guarantee being indexed, and being indexed does not guarantee ranking well. But nothing happens without the first stage. If the crawler cannot access a page, it simply does not exist for the search engine, no matter how good the content is.
The main web crawlers (and the new AI bots)
Every major platform has its own crawler, and knowing the main ones helps you read the visits that show up in the server logs. The most relevant today:
| Crawler | Whose it is and what it does |
|---|---|
| Googlebot | Google's crawler, feeds the largest search index in the world. |
| Bingbot | Microsoft's Bing crawler. |
| GPTBot | OpenAI's bot, collects content to train AI models. |
| ClaudeBot and PerplexityBot | Crawlers of AI assistants that fetch content to answer and cite. |
The big shift of recent years was exactly the arrival of artificial intelligence crawlers. Besides fetching to index, they fetch to train models and to generate real time answers, which turns the decision to allow or block each bot into a strategic content choice.
How to control what the crawler accesses
You are not at the crawler's mercy: there are several ways to guide where it goes and what it does with what it finds. The main tools:
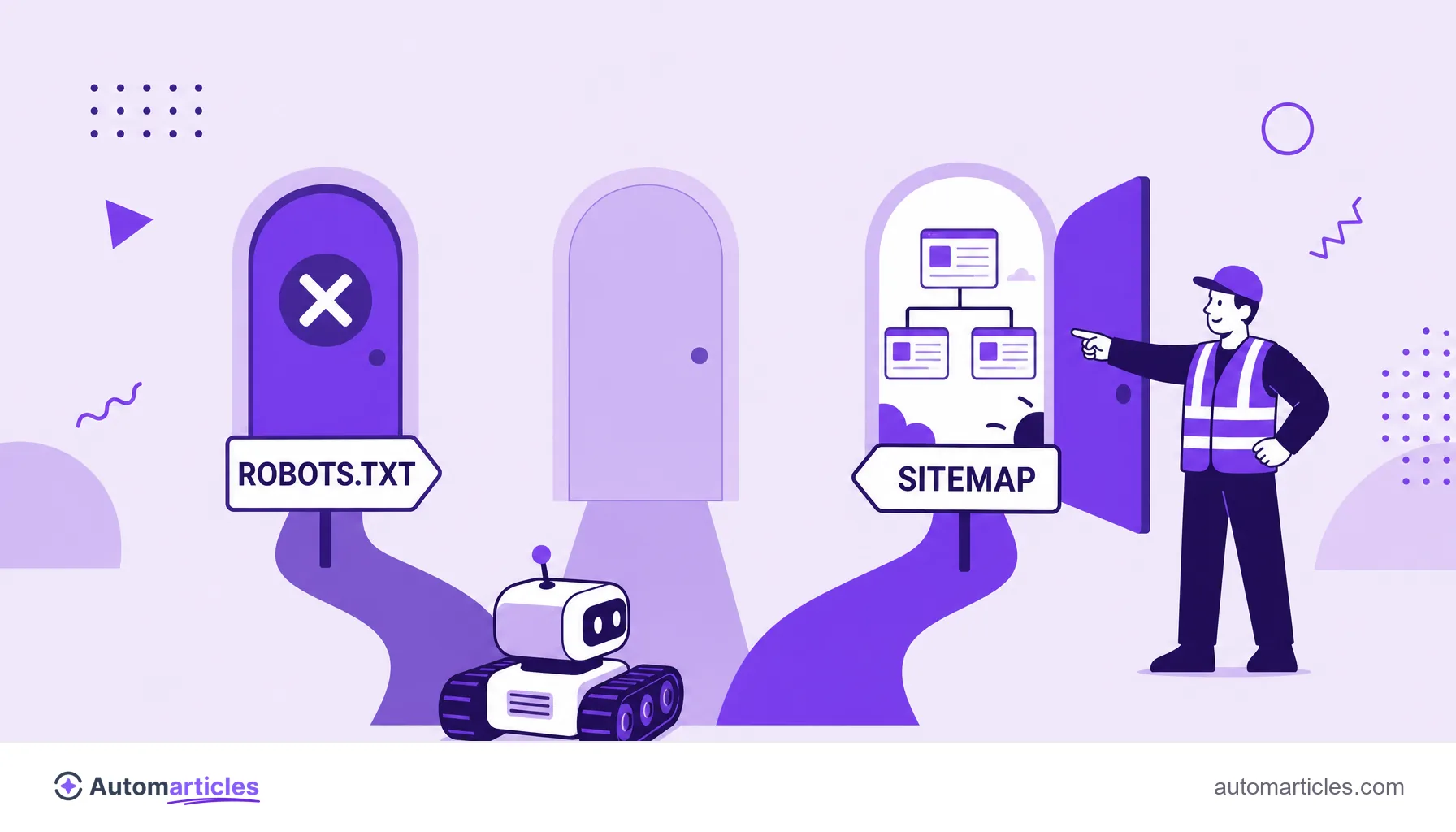
- robots.txt: the robots.txt file tells bots which areas of the site they may or may not crawl.
- Sitemap: the XML sitemap hands the crawler an organized list of the important URLs, making discovery easier.
- Crawl budget: on large sites, minding the crawl budget makes sure the bot spends its time on the pages that matter.
- Noindex: the noindex directive lets the crawler read the page but asks it to stay out of the index.
A warning worth gold: robots.txt and noindex solve different problems. Robots.txt prevents crawling; noindex prevents indexing. Blocking a page you wanted to deindex in robots.txt stops the bot from seeing the noindex, and it backfires.
Is a crawler illegal? Good bots and bad bots
Crawling the public web is not, in itself, illegal. Search engines do it all the time, and it is thanks to these bots that the internet is searchable. The line between a legitimate bot and a problematic one lies in the behavior, not in the technology.
A good crawler identifies itself, respects robots.txt, controls how often it visits so as not to overload the server, and collects only public content. Practices such as ignoring robots.txt, scraping personal or protected data, bypassing logins or taking a site down with too many requests can indeed break terms of use and laws, and that is where the risk lives.
The scale of automated traffic helps explain the concern. The Imperva bad bot report estimated that almost half of all internet traffic (49.6% in 2023) came from bots, not people. Not every bot is welcome, which is why telling a search engine crawler apart from an abusive scraper is part of the job of anyone who runs a site.
How to make the crawler's job easier on your site
The easier it is for the crawler to find and understand your pages, the greater the chance they get indexed fast. A practical checklist:
- Keep an updated sitemap: it is the map that points the bot to the right pages.
- Nail your internal links: pages with no link pointing to them (the orphans) are hardly ever discovered.
- Mind speed: pages that load fast let the bot crawl more in less time.
- Avoid dead ends: fix broken links and redirect chains that waste crawling.
- Check access: the URL inspection tool shows how Googlebot sees a specific page.
In the end, helping the crawler is helping yourself. A clean, fast and well linked architecture is easy for bots to read and, not by chance, also offers a better experience for people.