TF-IDF: qué es y cómo funciona en el SEO
Por Tiago CostaActualizado el 2 de julio de 2026

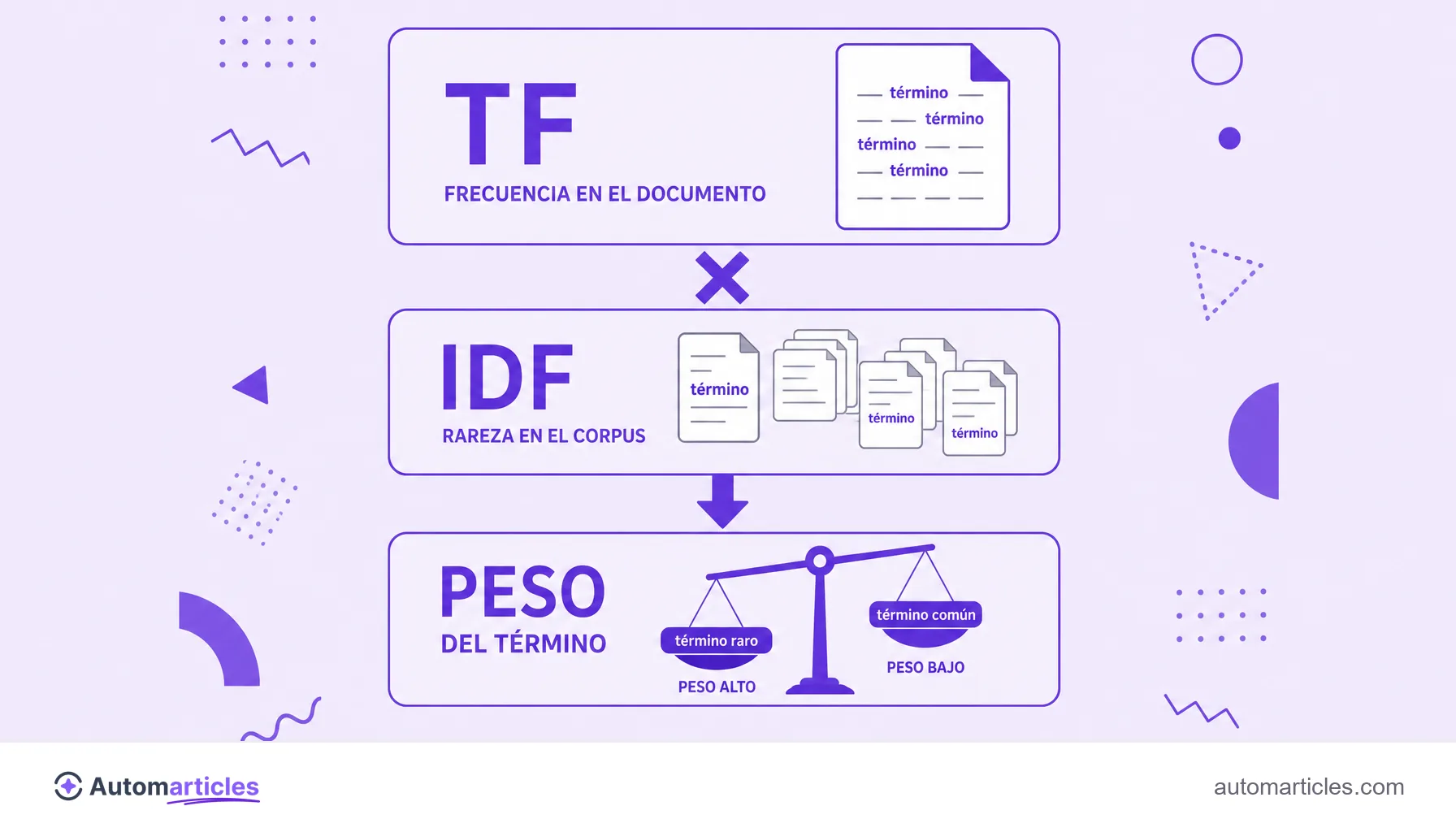
TF-IDF combina dos medidas para calcular el peso de una palabra en un texto:
- TF (Term Frequency): cuántas veces aparece el término en el documento;
- IDF (Inverse Document Frequency): cuán raro es el término en el corpus entero.
Al multiplicar ambas, las palabras frecuentes en la página y raras en la web reciben un peso alto, mientras que palabras comunes como "de" y "para" reciben un peso bajo.
Qué es TF-IDF y qué significa la sigla
TF-IDF es la sigla de Term Frequency, Inverse Document Frequency, es decir, frecuencia del término por la frecuencia inversa en los documentos. Es una medida estadística clásica de la recuperación de información, creada para responder a una pregunta simple: dentro de un texto, ¿qué palabras importan de verdad para describir el asunto?
La intuición es fácil de captar. Si la palabra fotosíntesis aparece varias veces en un artículo y casi no aparece en los otros textos de la colección, es una gran pista del tema de ese artículo. En cambio, palabras como de, que y para aparecen en casi todo, así que no ayudan a distinguir un documento de otro y reciben un peso bajo.
Por eso el TF-IDF se convirtió en la base de motores de búsqueda antiguos, filtros de spam y sistemas de recomendación. Transforma el texto en números que se pueden comparar, el primer paso para que una máquina entienda de qué habla una palabra clave.
Cómo funciona la fórmula del TF-IDF
El TF-IDF es el producto de dos componentes calculados por separado y luego multiplicados.
El TF (Term Frequency) mide la frecuencia del término en el documento. En su forma más común, es el número de veces que aparece la palabra dividido por el total de palabras del texto, para no penalizar documentos cortos ni inflar los largos.
El IDF (Inverse Document Frequency) mide cuán raro es el término en el corpus. Es el logaritmo del total de documentos dividido por el número de documentos que contienen ese término. Cuanto más raro el término, mayor el IDF; cuanto más común, más se acerca el IDF a cero.
El resultado final es TF x IDF. Una palabra solo alcanza un peso alto cuando es frecuente en ese texto y poco común en el conjunto. Si es frecuente en todas partes, el IDF baja el valor. Si es rara en la colección, pero ni aparece en el documento, el TF anula el cálculo.
TF-IDF en la práctica: un ejemplo paso a paso
Imagina un corpus de 1.000 artículos de un blog. Quieres saber el peso de las palabras en un post sobre café de especialidad. Mira tres términos de ese post:
| Término | Apariciones en el post | Documentos con el término | Peso relativo |
|---|---|---|---|
| de | 40 | 1.000 | Bajo |
| café | 18 | 300 | Medio |
| tueste | 9 | 25 | Alto |
La palabra de aparece mucho, pero está en los 1.000 documentos, así que el IDF la lleva casi a cero. Café es relevante, pero aparece en buena parte del blog, lo que reduce su peso. Tueste, presente en solo 25 textos, gana el mayor peso relativo: es la palabra que mejor caracteriza ese post específico.
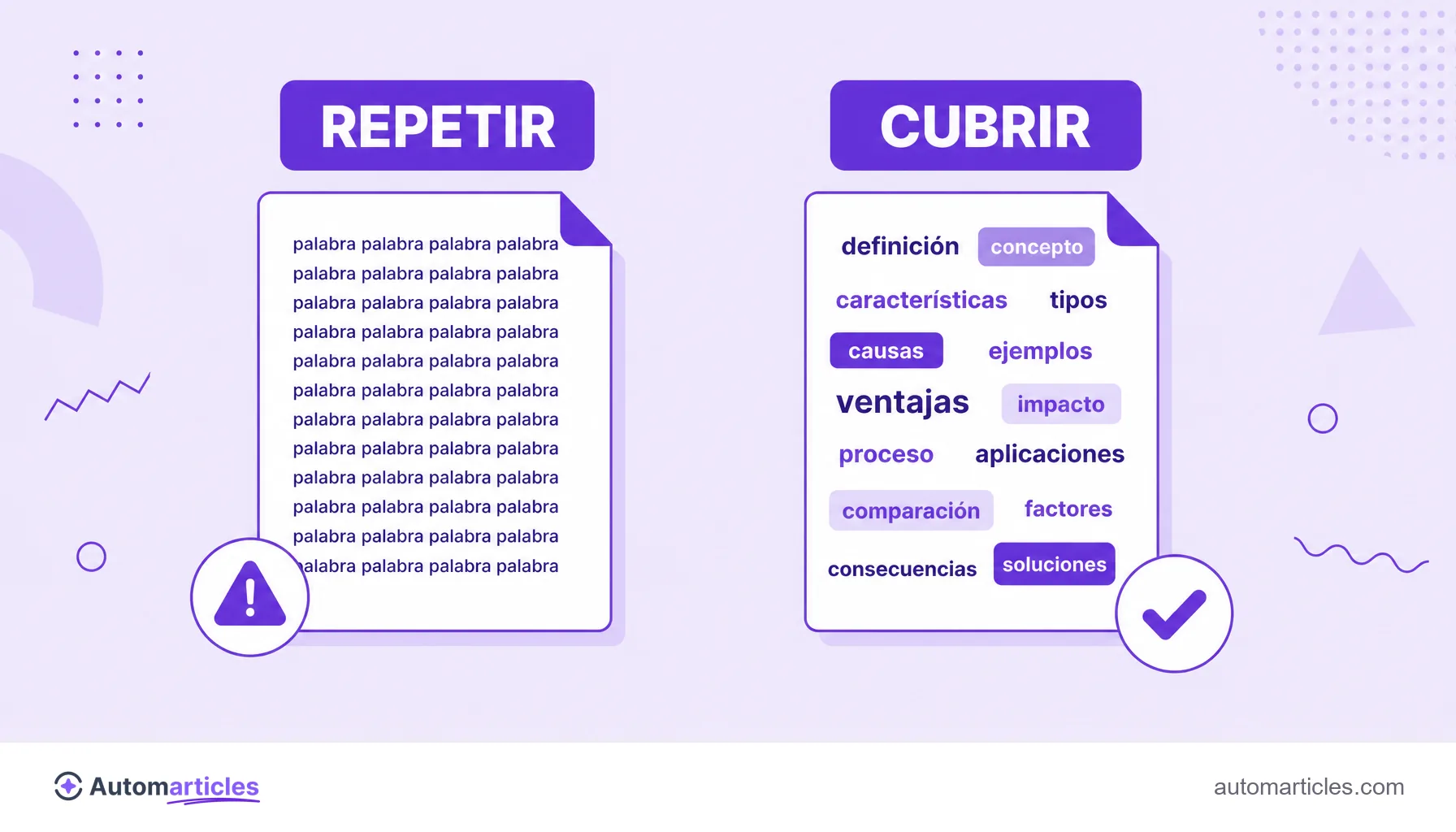
Este razonamiento explica por qué llenar el texto con el término principal no funciona. Repetir la palabra objetivo aumenta el TF, pero no cambia el IDF, y además choca con el keyword stuffing, la repetición artificial de palabras. Lo que enriquece el contenido es la presencia natural de los términos de apoyo, los que dan profundidad al tema.
TF-IDF en SEO: para qué sirve de verdad
Un aviso importante: el TF-IDF no es un factor de posicionamiento directo de Google. El propio Google ya restó peso a su papel. En declaraciones recopiladas por Search Engine Journal, John Mueller describió el TF-IDF como una métrica muy antigua y afirmó que ni siquiera es totalmente calculable, ya que dependería de las estadísticas de toda la web. El buscador moderno usa modelos de lenguaje y señales mucho más sofisticadas.
Aun así, el razonamiento detrás del TF-IDF sigue siendo útil como herramienta de análisis. Ayuda a mapear el vocabulario que usan los contenidos que ya posicionan para cubrir un tema, revelando términos de apoyo que quizá falten en tu texto. Es un apoyo al SEO semántico, no un objetivo en sí mismo.
En la práctica, las herramientas de optimización de contenido usan variaciones del TF-IDF para sugerir palabras relacionadas. El error es tratar la lista como una meta que cumplir. El uso sano es como una checklist de cobertura: si el tema pide subtemas que olvidaste, el TF-IDF enciende la luz.
TF-IDF, densidad de palabra clave y LSI: qué es diferente
Estos tres conceptos son fáciles de confundir, pero miden cosas distintas.
- TF-IDF: pesa un término en el documento contra un corpus entero. Es relativo y considera el resto de la colección.
- Densidad de palabra clave: la densidad de palabra clave es solo el porcentaje de veces que un término aparece en un texto, sin comparar con nada externo.
- LSI: el concepto de LSI (indexación semántica latente) intenta descubrir relaciones de significado entre términos, yendo más allá del conteo simple.
A la escala y en el idioma de la web real, ninguno de estos cálculos se hace en la forma pura que describen los manuales. Sirven mejor como modelos mentales: el TF-IDF recuerda que la relevancia es relativa, la densidad alerta contra el exceso, y el LSI refuerza la idea de cubrir un tema por significado, no por repetición.
Cómo usar el razonamiento del TF-IDF en tu contenido
No necesitas calcular logaritmos para beneficiarte de la idea. Una guía práctica:
- Estudia a quien ya posiciona: lista los términos de apoyo recurrentes en los textos de arriba y ve qué falta en el tuyo.
- Cubre el tema, no la palabra: en vez de repetir el término objetivo, trae variaciones, sinónimos y subtemas que el asunto pide.
- Evita el exceso: repetir la palabra principal no aumenta la relevancia percibida y puede parecer spam.
- Escribe para personas: un texto que responde bien a la duda suele incluir los términos correctos de forma natural.
- Usa herramientas como apoyo, no como regla: las listas de términos sugeridos ayudan a recordar huecos, pero el criterio final es la claridad para el lector.
Al final, el TF-IDF es más valioso como forma de pensar que como número a perseguir. Cubrir un asunto con profundidad y vocabulario rico es lo que el buscador recompensa, con o sin la fórmula en la mano.