Noindex: what it is and how to block indexing
By Tiago CostaUpdated on July 2, 2026

Noindex is a directive that keeps a page from appearing in the search results. In practice, noindex:
- is applied through a robots meta tag or the X-Robots-Tag HTTP header;
- makes the search engine drop the page from the index, even with links pointing to it;
- requires the page to stay crawlable, so the bot can read the instruction;
- should not be combined with a block in robots.txt.
What noindex is and what the directive does
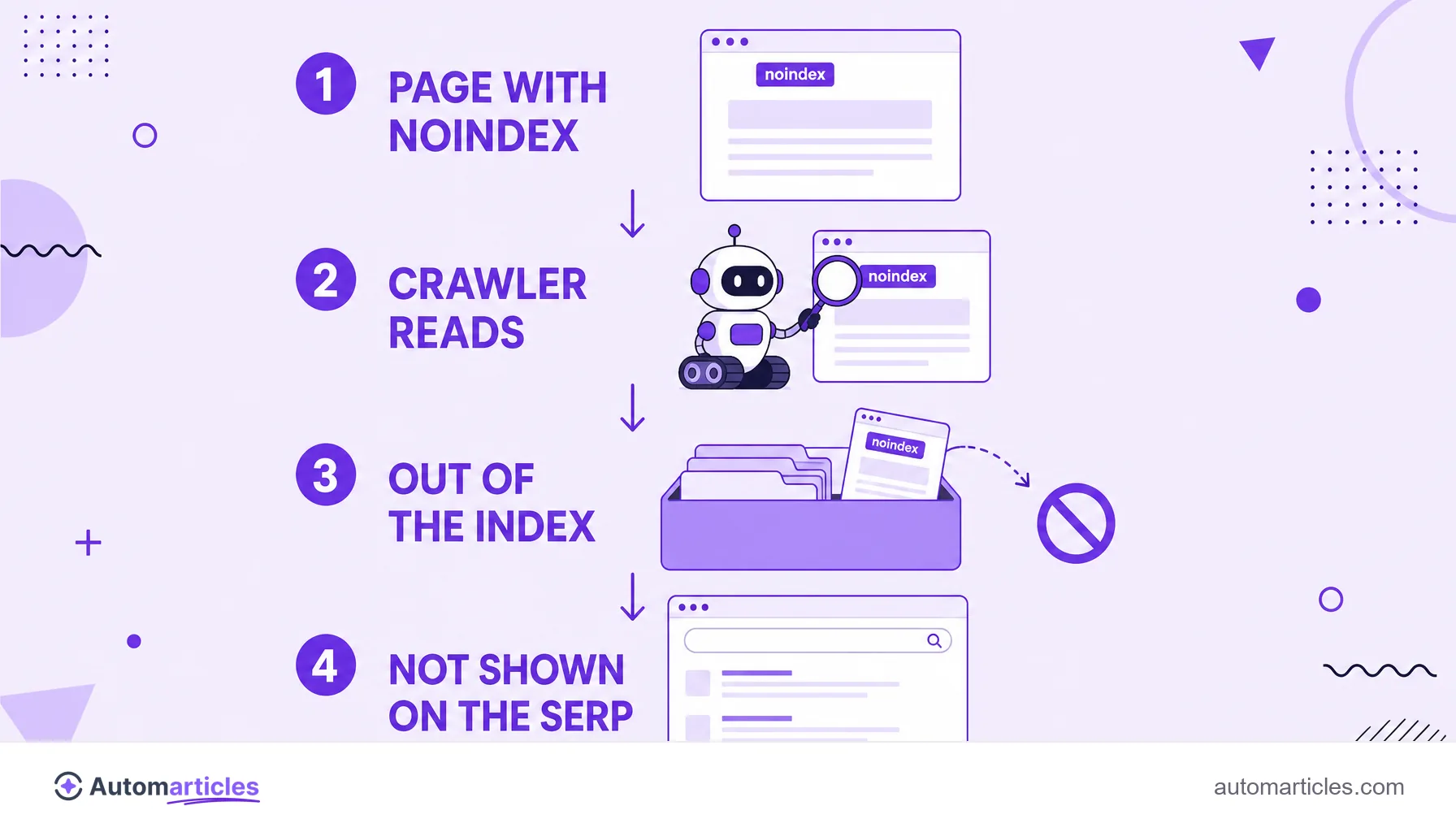
Noindex is an instruction you add to a page to tell search engines that it should not appear in the results. It is a robots directive: when Google crawls the page and finds the noindex, it drops that URL from the index and stops showing it in search, even if other pages link to it.
To understand noindex, it helps to separate two processes. First comes crawling, when the search engine bot visits the page. Then comes indexing, when the content is stored in the index so it can rank. Noindex acts precisely on this second process: the page may still be visited, but it stays out of the index.
That is why noindex is different from simply hiding content. The page stays live, accessible to anyone with the link, and can still be read by the crawler. What noindex does is one thing only, but a decisive one: it takes that URL out of the search results shop window.
How to apply noindex: robots meta tag and HTTP header
There are two official ways to apply noindex, and the choice depends on the type of file you want to block.
- Robots meta tag: the most common way, used on HTML pages. Just add the line <meta name="robots" content="noindex"> inside the <head> section of the code. To speak only to Google, swap robots for googlebot.
- X-Robots-Tag HTTP header: ideal for files that are not HTML, such as PDFs, images or spreadsheets, where there is no <head> section to hold the meta tag. In that case, the rule goes in the server response, as explained in the entry on the X-Robots-Tag header.
Both ways work alongside the other meta tags on the page and have the same effect: as soon as the search engine reads the instruction, it treats the URL as non indexable. The difference is only where the rule sits, in the HTML or in the server response.
Noindex vs robots.txt: the classic mistake
This is the most common misunderstanding in technical SEO, and it takes down pages that should disappear while keeping live pages that should go. The confusion arises because noindex and robots.txt seem to do the same thing, but they act at different stages.
- Robots.txt controls crawling: it tells the bot which URLs it may or may not visit.
- Noindex controls indexing: it tells the search engine not to store the page in the index.
The detail that breaks everything is this: to obey the noindex, the search engine needs to crawl the page and read the tag. If you block that same URL in robots.txt, the bot never visits it, never sees the noindex and, ironically, the page can keep showing up in search (only without a description). In other words, blocking a page you want to deindex in robots.txt is shooting yourself in the foot.
The practical rule is direct: if the goal is to take a page out of the results, use noindex and leave the URL free to be crawled. Robots.txt is there to save crawling on areas that do not even need to be read, not to deindex.
Noindex and nofollow: what each value does
The robots meta tag accepts more than one value at the same time, separated by a comma. Besides noindex, the most frequent partner is nofollow, which deals with the links on the page. It is worth knowing the combinations:
| Value | What it tells the search engine |
|---|---|
| index, follow | Default behavior: index the page and follow its links. |
| noindex, follow | Do not index this page, but follow the links to crawl the others. |
| noindex, nofollow | Do not index the page and do not follow any of its links. |
| index, nofollow | Index the page, but do not follow the links it contains. |
In most cases, when you only want to deindex a useful page (such as a thank you page that still leads the user to other places), the recommended value is noindex, follow: the page leaves search, but the crawl flow through the internal links continues.
When to use noindex (and when not to)
Noindex is an index hygiene tool. It is there to keep out of search the pages that exist for usability reasons but should not compete for traffic. Typical cases:
- Thank you and confirmation pages: the ones shown after a sign up or a purchase.
- Internal site search results: automatically generated pages that create repeated, low value content.
- Fragile tag and archive pages: on blogs and CMS platforms, many of these listings are thin content with no use for search.
- Test environments and admin areas: staging versions that must not leak into the index.
On the other hand, noindex does not solve everything. For duplicate content you want to consolidate (rather than remove from search), the path is usually the canonical URL, which points to the preferred version without hiding the page. And never place noindex on strategic pages: a noindex forgotten in production is one of the fastest ways to sink the traffic of an entire site.

How to check whether noindex is working
Applying noindex is easy; checking that it is actually taking effect is what sets good work apart. A simple routine:
- View the source code: open the page and look in the HTML for the robots meta tag with the noindex value, or check the HTTP header of the response.
- Make sure the URL is crawlable: confirm it is not blocked in robots.txt, otherwise the search engine will never read the tag.
- Use URL inspection: the URL inspection tool shows whether Google sees the page as excluded by the noindex tag.
- Track it in the report: in Google Search Console, the indexing report lists every URL that left the index because of noindex.
Once the page is reprocessed, it stops appearing in the results. The timing varies with how often the search engine crawls your site, so following the report avoids surprises.