ClaudeBot: what Anthropic's crawler is and how to control access to your site
By Tiago CostaUpdated on July 2, 2026

ClaudeBot is Anthropic's official crawler, the company that created the Claude assistant. In practice, ClaudeBot:
- visits public web pages and reads their content;
- collects that material to train and inform the Claude models;
- identifies itself with the ClaudeBot user-agent in server logs;
- respects robots.txt rules, so it can be allowed or blocked.
What ClaudeBot is
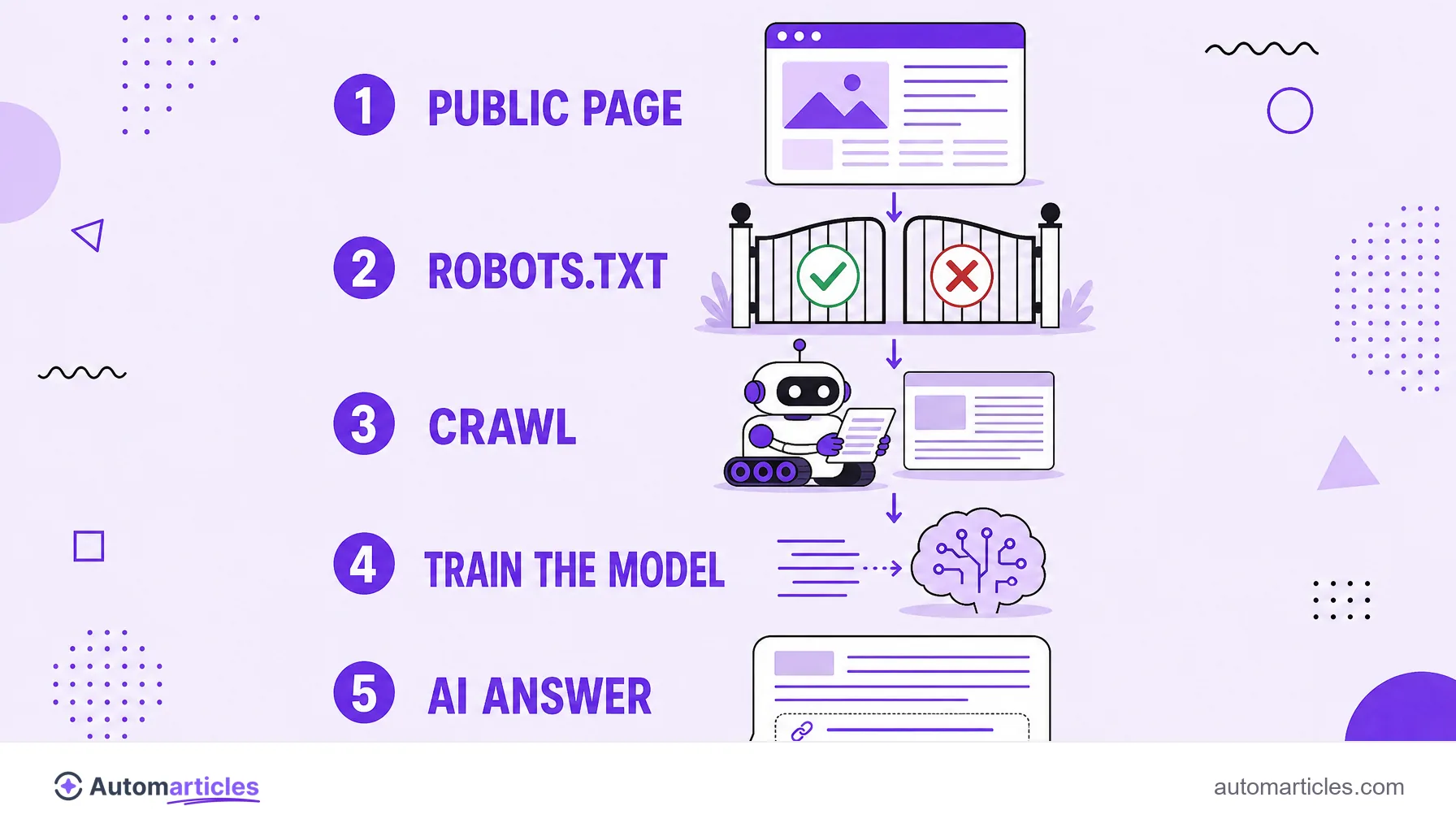
ClaudeBot is the automated crawler run by Anthropic, the company behind the model family and the AI assistant called Claude. Its job is simple to describe and enormous in scale: to travel the public web, download pages and extract text that becomes raw material to train and inform Anthropic's models.
In the hierarchy of internet robots, ClaudeBot is a crawler like any other. The difference is the destination of what it collects. While Googlebot reads pages to build a search index, ClaudeBot reads pages so a language model can learn from them and answer questions with more context. It is the same crawling mechanics in service of a new goal: generative artificial intelligence.
For anyone who owns a site, the key point is that ClaudeBot is neither hidden nor mysterious. It announces itself, publishes its IP ranges and obeys the instructions you leave on the server. In other words, you have control over what it can and cannot access.
What is ClaudeBot's user-agent
Every well-behaved crawler identifies itself with a line of text called the user-agent, which shows up in the server access logs. The user-agent of Anthropic's training crawler contains the word ClaudeBot, in a format similar to ClaudeBot/1.0 followed by an Anthropic contact address.
It helps to know that Anthropic runs more than one agent, each with a different purpose:
- ClaudeBot: the broad crawler that collects public content to train the models.
- Claude-User: triggers a fetch when a person, inside Claude, asks a question that requires checking the web in real time.
- anthropic-ai: an older identifier, still cited in some logs.
Being able to tell these names apart helps you read the logs accurately and write precise rules. Blocking only ClaudeBot, for example, has a different effect from blocking the agent that fetches on the user's behalf.
How to allow or block ClaudeBot in robots.txt
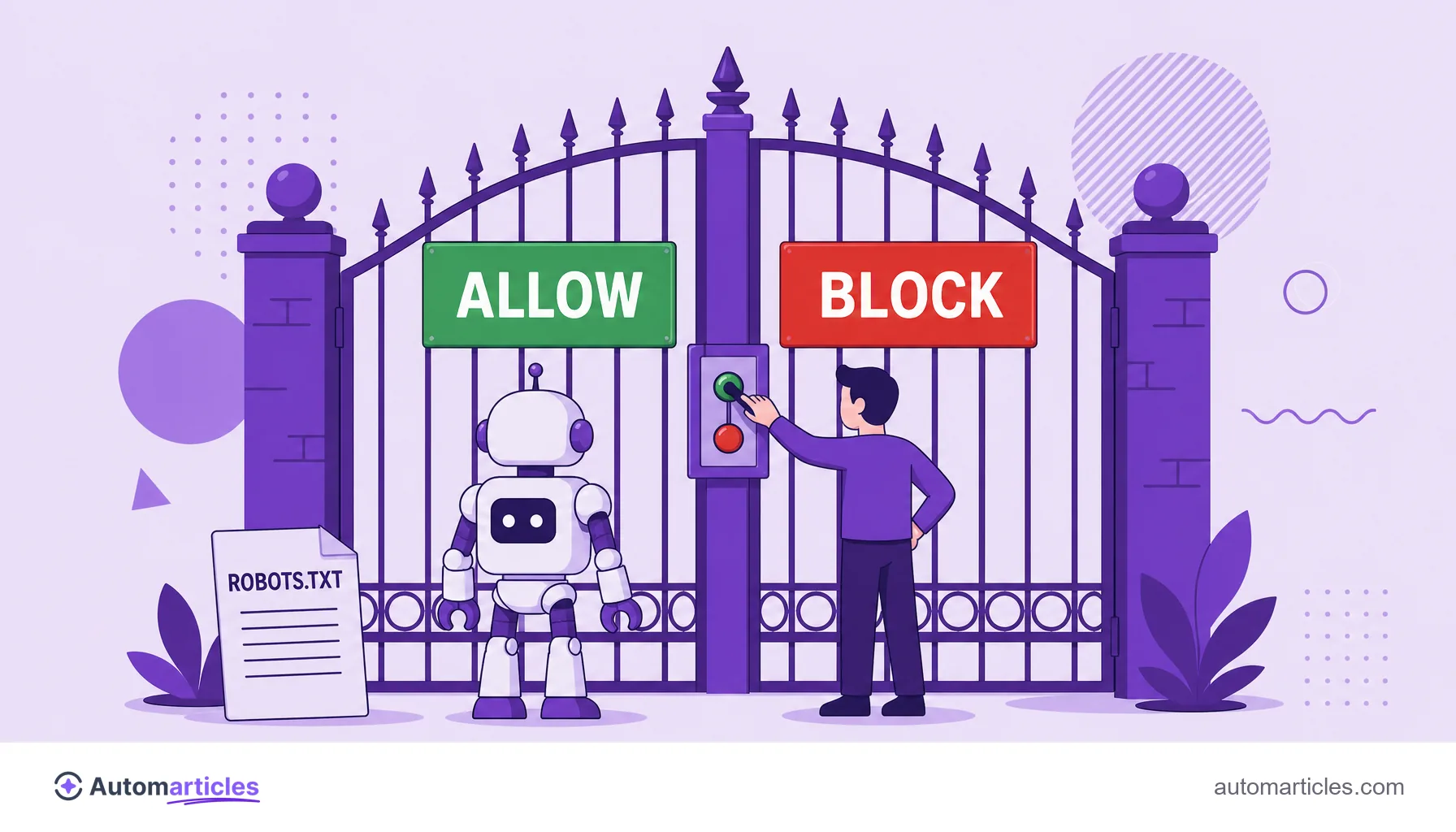
The most direct control over ClaudeBot lives in the robots.txt file, which sits at the root of the site and tells robots what they may or may not crawl. Rules are written per user-agent.
To block ClaudeBot entirely, add:
- User-agent: ClaudeBot
- Disallow: /
To allow access, simply do not create any blocking rule for it, or be explicit with Allow: /. Because ClaudeBot respects the protocol, a well written Disallow is enough to keep it off your site with no need for a firewall.
One precaution that saves headaches: robots.txt is a public guideline, and it only works with robots that choose to obey. ClaudeBot obeys, but malicious crawlers ignore the file. If the goal is to stop bots that do not cooperate, robots.txt needs backup at the server level or from an application firewall.
Is it worth blocking ClaudeBot? Training, rights and traffic
The decision to allow or block ClaudeBot has no single answer. It depends on what your content means to the business and on what you expect to receive in return for access.
There is a strong argument in favor of blocking: data on the economics of AI crawling reveals a very uneven trade. According to the traffic analysis by Cloudflare, in July 2025 Anthropic's crawlers visited around 38,000 pages for every visitor the company sent back to a site (a ratio that had been 286,000 to 1 in January of the same year). In other words, the bot reads a lot and refers few people back.
On the other hand, blocking has a cost: your content loses the chance to inform Claude's answers, an assistant with a large and growing user base. The scale of ClaudeBot shows the size of the bet. The same Cloudflare data pointed out that ClaudeBot reached around 21% of all AI crawler traffic on its network. The practical question is: do you want to be present in that universe or protect your content from training?
ClaudeBot and GEO: appearing (or not) in AI answers
This is where ClaudeBot meets GEO (Generative Engine Optimization), the discipline of optimizing content to be cited and used by AI search engines and assistants. The logic is direct: if Claude has never read your material, it can hardly mention your brand or use your arguments when answering a user.
Allowing ClaudeBot is therefore the first step to becoming eligible for this kind of AI citation. It guarantees nothing on its own, but it is the doorway. From there, the good practices of optimizing for generative engines apply: objective answers right at the start, data with a clear source, a scannable structure and definitions that are easy to extract.
A complementary resource has been gaining ground in this context: the llms.txt file, proposed as a guide for language models about which content on the site to prioritize. It does not replace robots.txt, but it signals intent and organization for those who want to be well represented by AI, rather than only blocking it.
How to confirm access really comes from ClaudeBot
Not every hit that claims to be ClaudeBot is legitimate. Since the user-agent is just text, any script can copy it to pose as Anthropic's bot. So, before making decisions based on the logs, it is worth confirming the origin.
Verification follows the same principle used for Googlebot:
- Check the IP range: Anthropic publishes the address ranges ClaudeBot uses. A hit that claims to be ClaudeBot but comes from outside those ranges is suspicious.
- Watch the behavior: the legitimate bot respects robots.txt and controls its request rate. Aggressive bursts that ignore your rules do not match an official crawler.
- Cross-check the logs: compare timestamps, volume and pages accessed to separate the real crawler from a disguised scraper.
This care is what separates an accurate reading of the data from a reaction to a false positive. Confirming the identity before blocking avoids both shutting the door on the right bot and letting in the wrong one.