OAI-SearchBot: what the ChatGPT search crawler is and how it differs from GPTBot
By Tiago CostaUpdated on July 2, 2026

OAI-SearchBot is OpenAI's crawler dedicated to ChatGPT search. In practice, it:
- discovers and indexes pages so they can be cited in ChatGPT search;
- is distinct from GPTBot (training) and ChatGPT-User (actions on the user's request);
- identifies itself with the OAI-SearchBot user-agent in server logs;
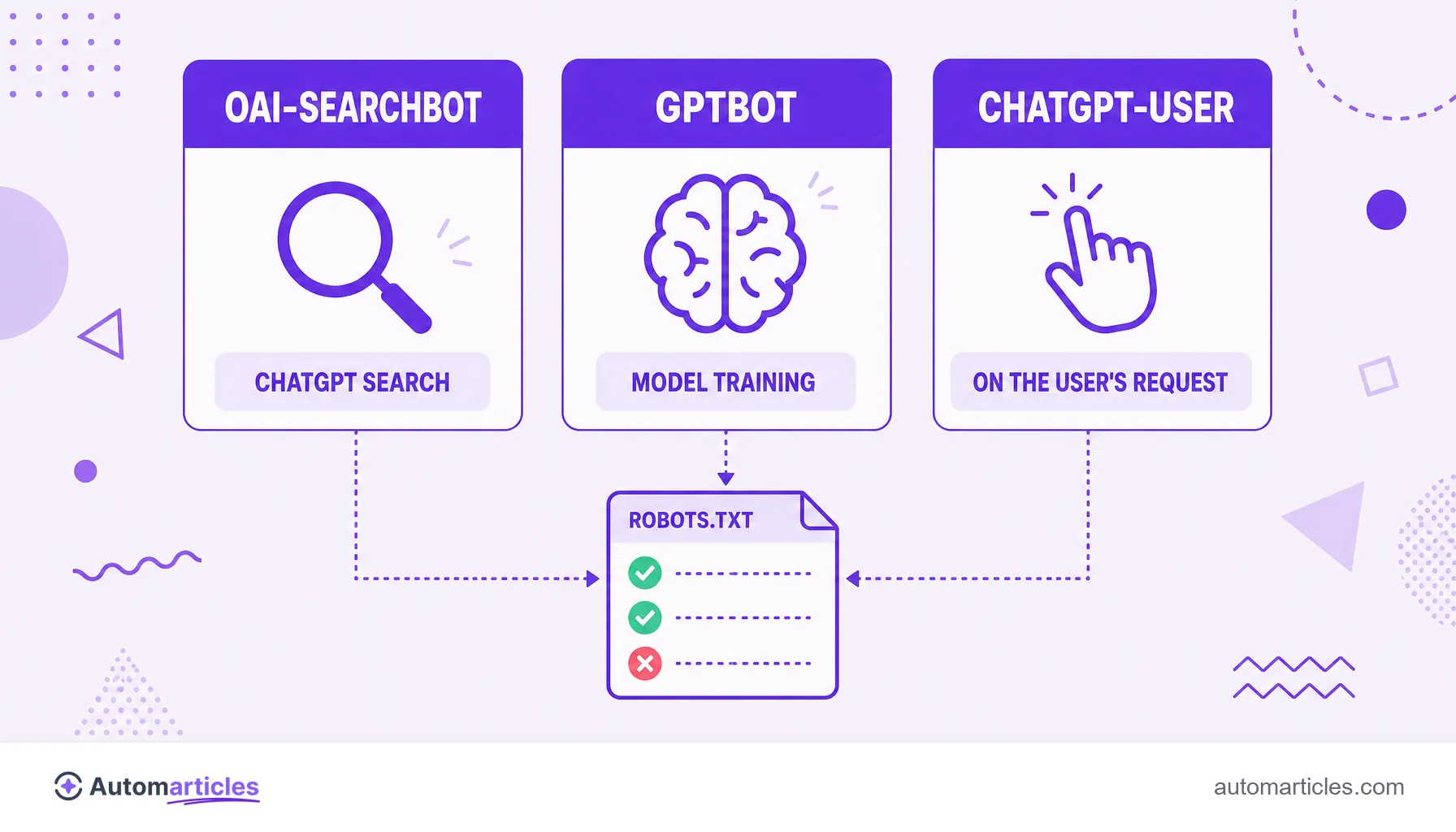
- respects robots.txt, so each OpenAI bot can be controlled separately.
What OAI-SearchBot is
OAI-SearchBot is the crawler OpenAI uses for the ChatGPT search feature. When ChatGPT needs to answer with current information, it queries an index of web pages, and OAI-SearchBot is what discovers, visits and maintains that index. In other words, it is to ChatGPT roughly what Googlebot is to Google.
Like any crawler, OAI-SearchBot travels public pages and reads the content. The crucial difference is the purpose: it does not collect text to train a model, but so your site can be found and cited when ChatGPT runs a search. Appearing in that index is what gives your content the chance to become one of the sources shown to the user, with a link back.
This separation of roles is OpenAI's big novelty and the reason it is worth knowing this bot's name in detail.
OAI-SearchBot, GPTBot and ChatGPT-User: OpenAI's three bots
OpenAI runs three different agents, and confusing them leads to the wrong blocking decisions. Each one has its own purpose:
| Bot | What it does |
|---|---|
| OAI-SearchBot | Discovers and indexes pages for ChatGPT search. Allowing it helps you appear as a cited source. |
| GPTBot | Collects public content to train OpenAI's models. Blocking it keeps your site out of training. |
| ChatGPT-User | Makes a one-off visit when a user requests an action that requires accessing that page on the spot. |
The practical consequence is powerful: since each bot has its own name, you can choose exactly what to allow. You can, for example, let your content appear in ChatGPT search while keeping it out of model training, something the next section shows in practice.
What is OAI-SearchBot's user-agent
In the server logs, this crawler appears with a user-agent that contains the text OAI-SearchBot, in a format similar to OAI-SearchBot/1.0 followed by an OpenAI contact address. The other two agents appear as GPTBot and ChatGPT-User, each with its own line.
Reading these three identifiers carefully avoids common mistakes. Many people block GPTBot thinking that removes them from ChatGPT search, when in fact what controls the presence in search is OAI-SearchBot. Since the user-agent is just declared text, the definitive confirmation that a hit is legitimate comes from cross-checking the name with the IP ranges published by OpenAI, not only from the log line.
How to appear in ChatGPT search without allowing training
This is the most interesting move the bot split enables. Since robots.txt rules are written per user-agent, you can treat each OpenAI bot differently. To block training but stay in ChatGPT search, you block GPTBot and allow OAI-SearchBot:
- User-agent: GPTBot
- Disallow: /
- User-agent: OAI-SearchBot
- Allow: /
For the opposite scenario, leaving ChatGPT search, use Disallow: / in the OAI-SearchBot block. And remember that blocking GPTBot does not remove your site from search, just as allowing OAI-SearchBot does not authorize the use of your content for training. They are independent controls, and it is exactly this independence that makes the access policy a strategic choice, not a single on and off switch.
How much OpenAI crawls and how much it gives back
Before deciding, it is worth looking at the numbers of the trade. OpenAI is today one of the most active crawlers on the web. According to the analysis by Cloudflare, GPTBot reached around 30% of all AI crawler traffic on its network, the largest share among the AI bots tracked.
The other side of the ledger is the return in visits. The same Cloudflare estimated that, in July 2025, OpenAI's crawlers visited around 1,091 pages for every visitor referred back to a site. That is a far less uneven ratio than that of other AI players, which makes sense for a company running a search that displays and links sources, but it still shows that the volume of crawling far outweighs the traffic sent back.
The practical reading is balanced: ChatGPT search already has enough scale to be worth the presence, and the ideal access policy is usually to allow OAI-SearchBot to gain visibility and decide calmly what to do with GPTBot.
OAI-SearchBot and GEO: getting cited in ChatGPT search
For GEO (Generative Engine Optimization), OAI-SearchBot is the bot that matters. It is the doorway to ChatGPT search, and allowing it is the prerequisite to compete for space among the cited sources. Blocking it, on the contrary, means giving up that showcase.
Allowing access, however, is only the beginning. Winning the AI citation depends on applying the practices of optimizing for generative engines: answer the question directly and up top, back up claims with data from a clear source, use headings and lists that make extraction easy, and cover the topic with real depth. The easier it is for the model to understand and trust your answer, the greater the chance it picks your link.
A resource that complements this strategy is the llms.txt file, proposed to guide language models about which content on the site to prioritize. It does not replace robots.txt, but it reinforces the signal of organization and helps those who want to be well represented in AI answers, not just indexed.