Google Knowledge Graph: what it is and how it works
By Tiago CostaUpdated on July 2, 2026
The Knowledge Graph is Google's knowledge base that connects entities and facts to understand the world beyond words. In practice, it:
- treats people, places and things as entities, not as text;
- links those entities by relationships and attributes;
- feeds the knowledge panel and direct answers in search;
- helps Google disambiguate terms with the same name;
- is an increasingly used base to generate AI answers.
What the Google Knowledge Graph is
The Knowledge Graph is the huge database that Google uses to represent the world as a network of entities and facts. Instead of treating a search as a pile of words, the search engine understands that there is a real thing behind them: a person, a place, a company, a movie, a concept. Each of these things is an entity, and the graph stores what is known about it and how it connects to others.
Launched in 2012, the Knowledge Graph marked Google's shift from a text matching engine to a meaning understanding engine. According to Google itself, the graph already holds billions of entities and a much larger number of facts that connect them, feeding everything from quick answers to the organization of results.
It is this entity based understanding that supports much of modern semantic SEO: the goal stops being just to repeat the right word and becomes making clear, to the machine, which entity your content represents and what it connects to.
Knowledge graph as a technology: entities, relationships and graphs
Before being a Google product, a knowledge graph is an information technology concept. It models knowledge as a graph: points called nodes (the entities) linked by lines called edges (the relationships). The famous triple is subject, predicate, object, as in "Machado de Assis (subject) wrote (predicate) Dom Casmurro (object)".
This model is used far beyond search. Companies build their own knowledge graphs to connect customer, product and process data, and graph database tools, such as Neo4j, are made precisely to store and query these relationships efficiently. There is no single best knowledge graph: the right one depends on the problem, the volume of data and how the entities need to relate.
The Google Knowledge Graph is, therefore, a giant, public example of this idea, applied to the entire web. Understanding the logic of nodes and relationships helps to see why the consistency of your data (name, category, links) matters so much to the search engine.
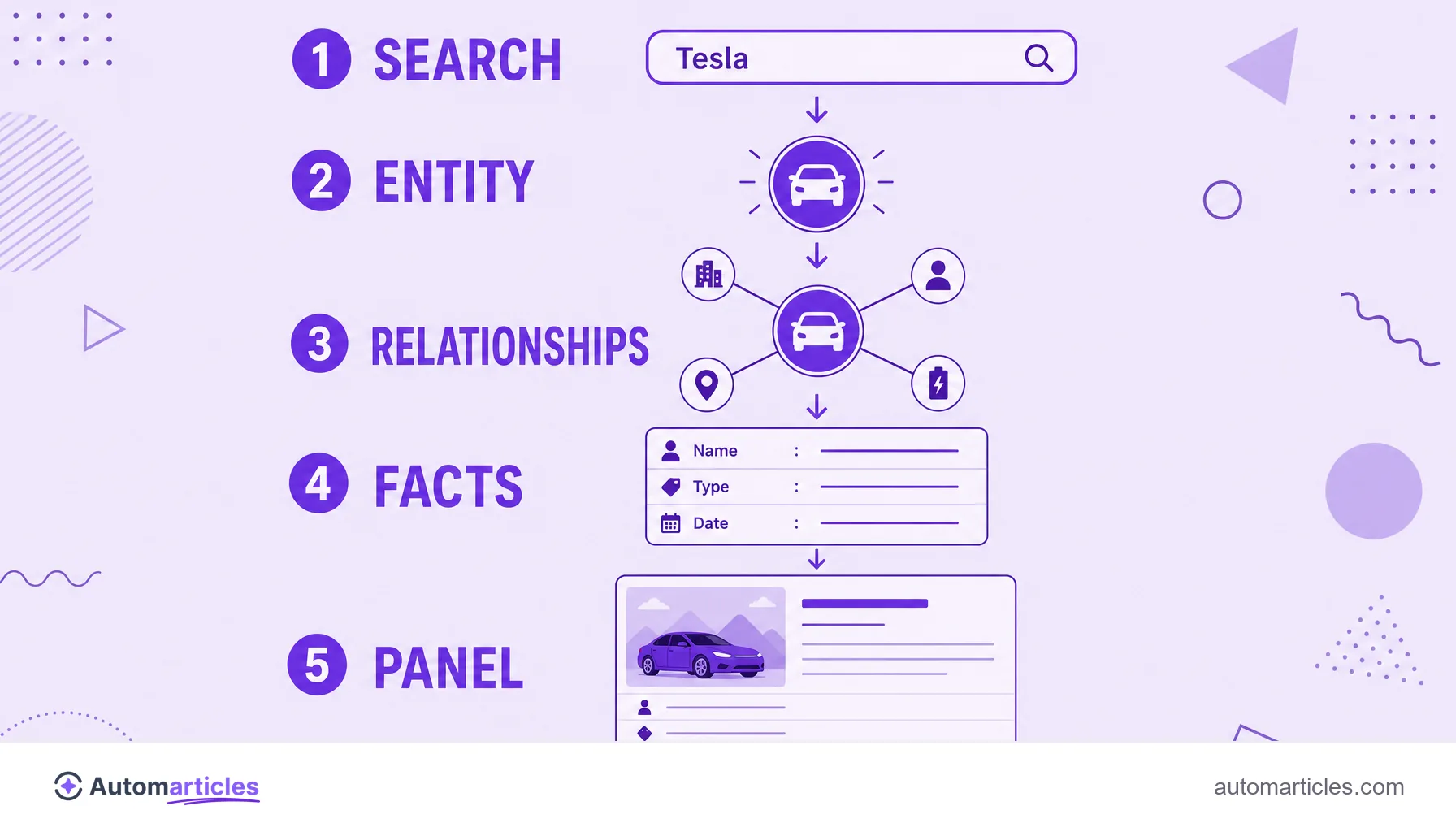
From words to entities: how Google understands the world
The great advantage of the knowledge graph is solving the ambiguity of language. The word "jaguar" can be an animal, a car or a team. Because Google treats each meaning as a distinct entity, it can interpret the intent by the context of the search and show the right answer.
This entity based understanding brings practical effects to search:
- Direct answers: questions like "height of the Eiffel Tower" are answered on the spot, because the fact is in the graph.
- Disambiguation: the search engine separates people and brands with the same name, offering the most likely result.
- Suggested relationships: when searching for an author, their books, contemporaries and related works appear.
- Connection to structured data: the structured data markup on your site helps Google link your content to the right entities.
For SEO, the takeaway is clear: the more your content covers a topic as a cohesive set of entities and subtopics, the more it reinforces your topical authority in the eyes of the search engine.
The knowledge panel on the SERP
The most visible face of the Knowledge Graph is the knowledge panel, that block that appears on the right (or at the top, on mobile) when you search for a known entity, such as a company, a celebrity or a place. It gathers, in a single card, the main facts the graph holds about that entity: description, image, official website, social profiles, data and related links.
The panel is not an ad nor a common organic result. It is assembled automatically by Google from the graph, cross-referencing trusted sources. That is why you do not buy a knowledge panel: you earn it by becoming a recognized and well described entity on the web.
For brands, showing up with a complete and correct panel conveys immediate authority and occupies a prime spot on the SERP, alongside the sitelinks and other features that reinforce a domain's presence in search.

Where Google gets the graph's facts
The Knowledge Graph feeds on many cross-referenced sources, and understanding where the data comes from shows where you can influence it. The main origins are:
- Open and trusted databases: collaborative repositories of structured facts about entities, used as a broad reference by the search engine.
- Structured data from your site: markup with schema markup of types like Organization and Person tells Google, explicitly, who the entity behind the site is.
- Consistent information on the web: the same name, address and phone everywhere (the NAP standard) reinforces a business's identity.
- Trust signals: mentions, links and reputation feed E-E-A-T and help Google trust the facts it associates with you.
For local businesses, keeping the Google Business Profile complete and verified is one of the most direct ways to feed the graph with correct data and earn a consistent knowledge panel.
Knowledge Graph, zero-click search and AI answers
The knowledge graph is the base that lets Google answer directly, without sending the user to a link. This started with quick answers and panels, and reached its peak with AI Overviews and generative search, which synthesize entities and facts into a summary at the top of the page.
This movement has a cost for organic traffic. According to the SEO statistics roundup by Ahrefs, the presence of an AI Overview is associated with a click-through rate around 58% lower for the top-ranking organic page. In other words, when Google answers on the SERP itself, fewer clicks are left for the results.
The strategic reaction is not to ignore the graph, but to play in its favor. Being recognized as an entity and being cited inside these answers becomes as valuable as ranking, which brings traditional SEO closer to the new fronts of AI citation and AI brand mention.
How to earn a place in the Knowledge Graph
You do not control the Knowledge Graph, but you can provide clear signals so that Google understands and trusts your entity. A practical roadmap:
- Mark your entity with schema: use structured data for Organization or Person, with the official name, logo, website and social profiles linked by the sameAs property.
- Be consistent across the web: use exactly the same name, category and contact details on your site, social profiles and directories, following the NAP standard.
- Build real reputation: earn mentions and links from relevant sources, the foundation of E-E-A-T and of the trust that supports a panel.
- Cover your topic in depth: deep, interlinked content signals that you are a reference, reinforcing your entity and your topical authority.
- Care for official profiles: keep the Google Business Profile and public databases updated, since the graph cross-references these sources.
The result is not immediate, but it is cumulative. The sharper and more coherent your digital identity, the greater the chance that Google will turn you into an entity in the graph, with its own answers and panel.