URL canônica: o que é e como resolver conteúdo duplicado
Por Tiago CostaAtualizado em 2 de julho de 2026

URL canônica é a versão preferida de uma página que o buscador deve indexar quando existem endereços duplicados. Na prática, a URL canônica:
- é indicada pela tag rel=canonical no HTML da página;
- diz ao Google qual endereço tratar como original;
- concentra nessa versão a autoridade dos links;
- resolve conteúdo duplicado sem remover as outras páginas.
O que é uma URL canônica
URL canônica é o endereço que você escolhe como a versão oficial de uma página quando o mesmo conteúdo, ou um conteúdo muito parecido, pode ser acessado por mais de uma URL. Em vez de deixar o buscador decidir sozinho qual delas mostrar, você aponta a preferida, e as demais passam a ser tratadas como cópias que remetem à original.
A indicação é feita por uma tag chamada rel="canonical", colocada no cabeçalho HTML das páginas duplicadas. Ela funciona como um bilhete para o buscador: a versão que vale para indexação e para ranquear é esta aqui, não as outras. O termo vem de canônico, no sentido de oficial, aquilo que serve de referência.
Vale um cuidado com o vocabulário: você vai encontrar canonical, tag canonical e URL canônica falando da mesma coisa. Todos se referem ao mesmo mecanismo de escolher e sinalizar a versão principal de um conteúdo.
Por que o conteúdo duplicado é um problema
Conteúdo duplicado acontece quando o mesmo texto aparece em endereços diferentes, seja por versões com e sem www, parâmetros de rastreamento, páginas de produto que se repetem ou versões para impressão. Para o buscador, isso cria uma dúvida: qual dessas URLs deve aparecer nos resultados?
O problema é mais comum do que parece. Um estudo da Semrush, que analisou 100 mil sites e 450 milhões de páginas, apontou o conteúdo duplicado como o problema de SEO mais frequente, presente em cerca de metade dos sites avaliados. Ou seja, é uma armadilha que atinge a maioria dos projetos em algum momento.
Quando o Google encontra várias cópias sem orientação, ele pode dividir a força dos links entre elas, escolher a versão errada para exibir ou simplesmente gastar orçamento de rastreamento visitando páginas redundantes. A URL canônica resolve isso concentrando os sinais em um único endereço.
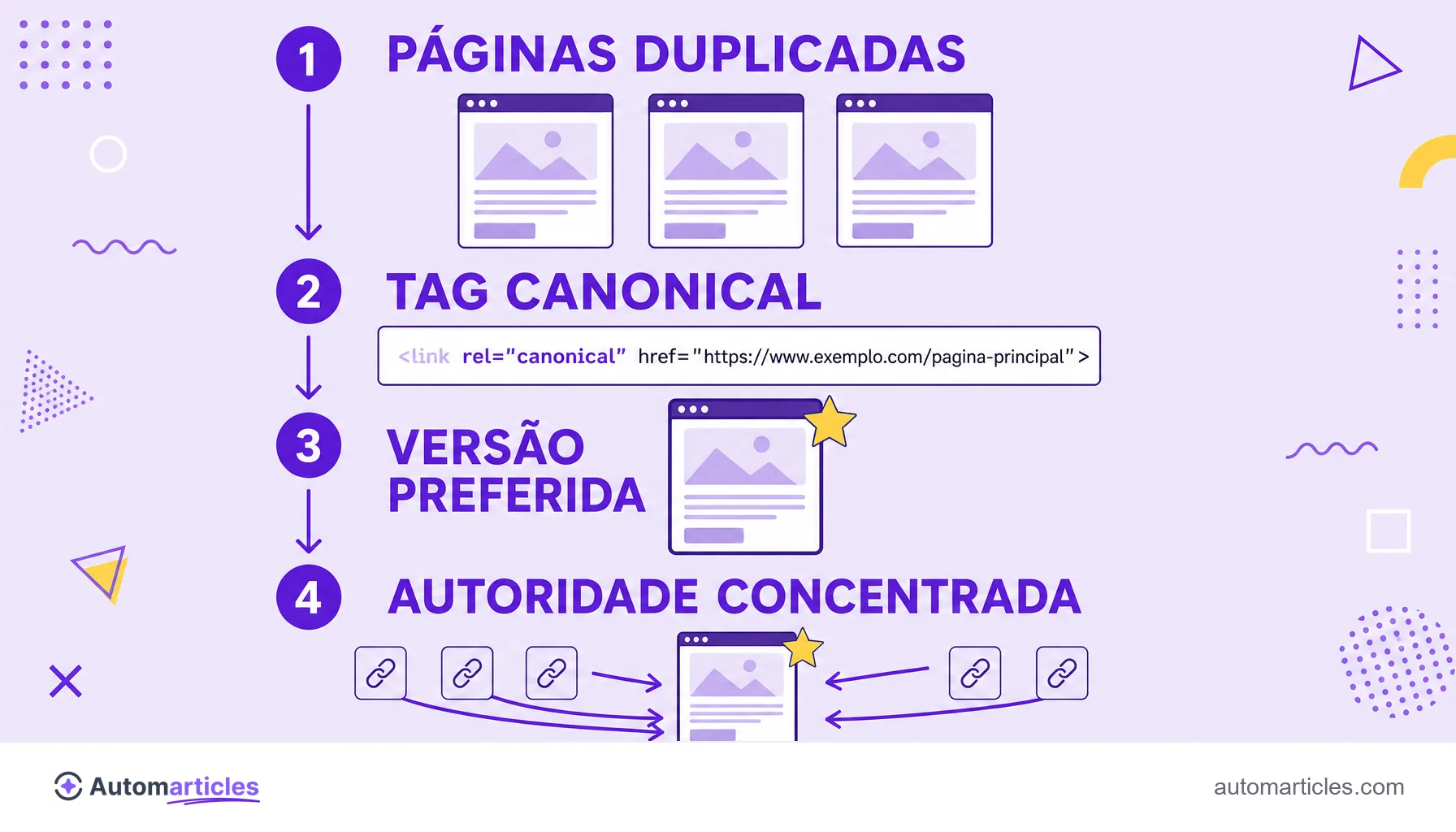
Como funciona a tag canonical
A tag canonical é uma linha simples no HTML, mas o efeito dela é grande. O formato é este: <link rel="canonical" href="https://seusite.com/pagina-oficial">, inserido dentro da seção <head> de cada versão duplicada, apontando para a URL preferida.
Ao ler essa marcação, o buscador consolida as páginas duplicadas na canônica. Na prática, isso significa que a força transmitida pelos links (o chamado link juice) e a relevância medida por algoritmos como o PageRank se concentram no endereço oficial, em vez de se dividirem entre cópias.
Dois pontos merecem atenção. Primeiro, a tag canonical é uma sugestão forte, não uma ordem absoluta: o Google pode escolher outra versão se os sinais apontarem para lá. Segundo, uma página pode apontar para si mesma como canônica, prática recomendada para deixar claro qual é a versão principal.
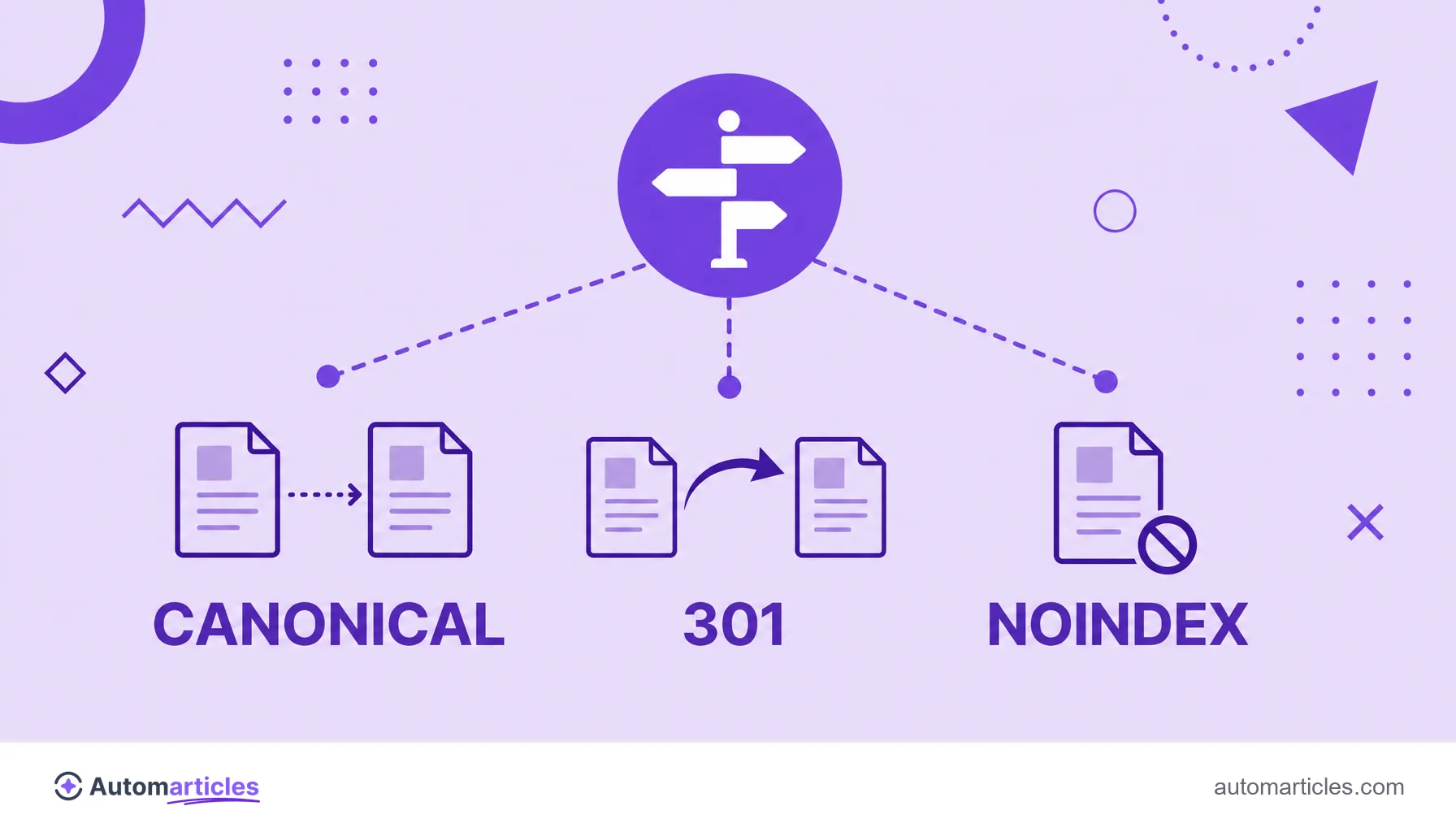
URL canônica, redirecionamento e noindex: quando usar cada um
Canonical não é a única forma de lidar com páginas semelhantes, e escolher a ferramenta errada custa tráfego. A regra geral separa três situações:
| Situação | Ferramenta ideal |
|---|---|
| Conteúdo duplicado que deve continuar acessível | Tag canonical apontando para a versão preferida |
| Página que mudou de endereço de forma permanente | Redirecionamento 301 |
| Página que não deve aparecer na busca de jeito nenhum | Diretiva noindex |
A diferença é importante: o canonical mantém as duas páginas no ar e apenas indica a preferida; o redirecionamento 301 leva o usuário e o buscador para o novo endereço; e o noindex tira a página dos resultados sem consolidar autoridade. Misturar canonical com noindex na mesma página, aliás, envia sinais contraditórios e deve ser evitado.
Erros comuns com a tag canonical
A tag canonical é poderosa justamente porque é fácil de errar. Os deslizes mais frequentes são:
- Apontar para a URL errada: canônicas que remetem a páginas inexistentes, quebradas ou irrelevantes confundem o buscador.
- Canonical em cadeia: a página A aponta para a B, que aponta para a C, criando um circuito que enfraquece o sinal.
- Bloquear a canônica no robots.txt: se o buscador não consegue rastrear a URL preferida, ele não lê a instrução.
- Ignorar parâmetros de URL: filtros e ordenações geram muitos endereços que precisam de canonical, como explica o verbete de parâmetros de URL.
- Confundir com hreflang: versões em idiomas diferentes não são duplicatas e devem usar hreflang, não canonical de uma para a outra.
Uma mensagem famosa do Google Search Console, a de que o buscador escolheu uma canônica diferente da indicada, costuma nascer justamente desses erros: os sinais da página contradizem a tag.
Como verificar a URL canônica de uma página
Conferir se a canônica está correta é rápido e evita surpresas no ranking. Um roteiro simples:
- Veja o código-fonte: procure no HTML pela linha rel="canonical" e confirme para qual URL ela aponta.
- Use a inspeção de URL: a ferramenta de inspeção de URL mostra a canônica declarada pela página e a que o Google de fato escolheu.
- Acompanhe o relatório de indexação: no Google Search Console, é possível ver quais páginas foram consolidadas em outra canônica.
- Cheque a consistência: garanta que a canônica, o sitemap e os links internos apontem todos para a mesma versão preferida.
Quando a canônica declarada e a escolhida pelo Google coincidem, é sinal de que a página está enviando sinais claros. Quando divergem, vale investigar qual sinal está puxando o buscador para outra URL.