Crawl Budget: o que é e como otimizar para SEO
Por Tiago CostaAtualizado em 2 de julho de 2026

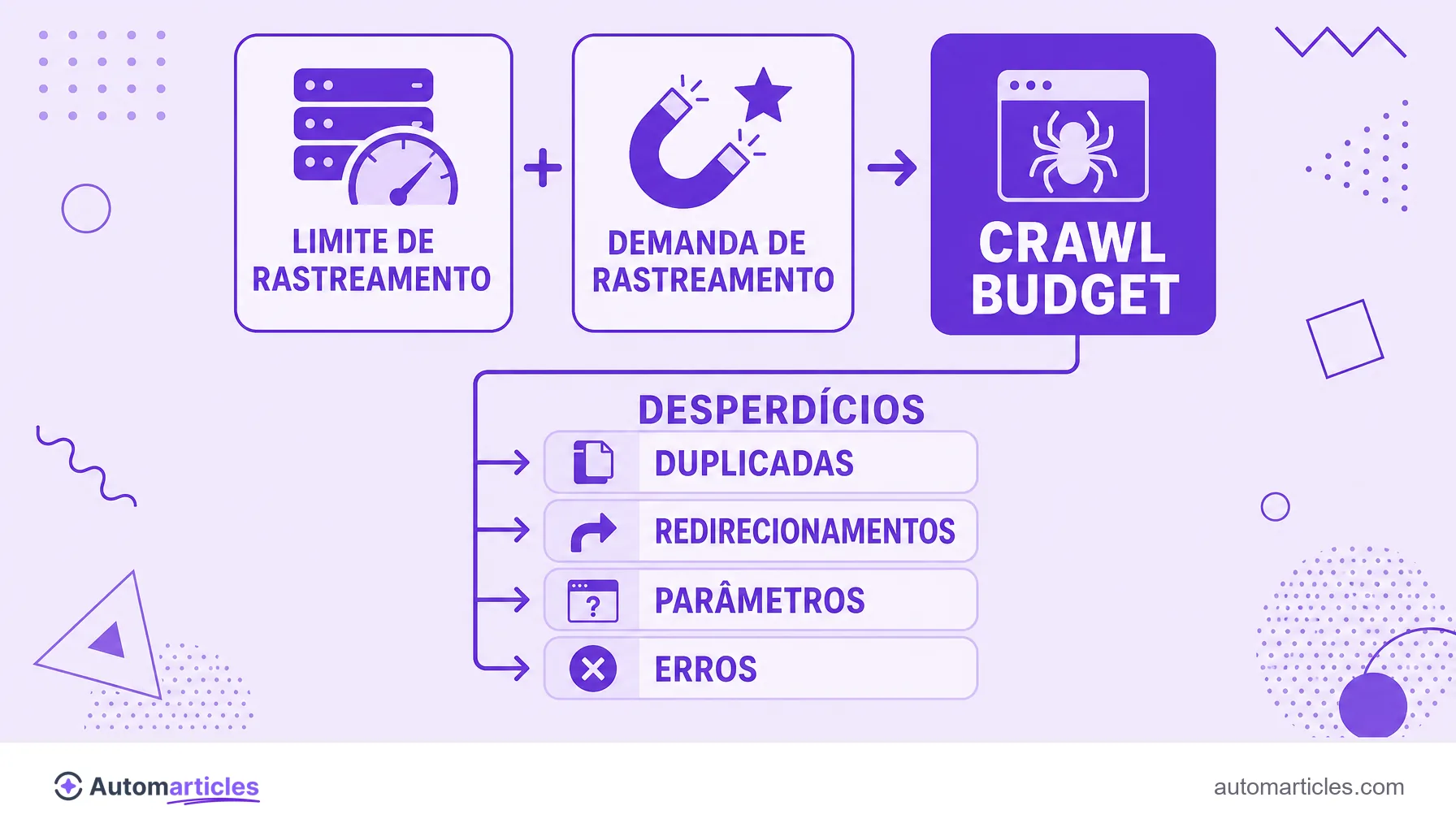
Crawl budget (orçamento de rastreamento) é o número de páginas que um buscador se dispõe a rastrear em um site num período. Ele depende de dois fatores:
- o limite de rastreamento, ligado à velocidade e à saúde do servidor;
- a demanda de rastreamento, ligada à popularidade e à frequência de atualização do conteúdo.
O que é crawl budget (orçamento de rastreamento)
Crawl budget, ou orçamento de rastreamento, é a quantidade de páginas que um buscador como o Google se dispõe a rastrear em um site dentro de um determinado período. É o limite prático de atenção que o robô, o crawler, dedica ao seu domínio antes de seguir para outros sites.
Esse orçamento não é um número fixo divulgado pelo Google. Ele surge da combinação de duas forças: o quanto o seu servidor aguenta ser visitado sem ficar lento e o quanto o buscador acredita que o seu conteúdo merece ser revisitado. Em sites com poucas páginas, o robô costuma dar conta de tudo com folga. Já em portais com dezenas de milhares de URLs, cada rastreamento passa a ser um recurso disputado.
Vale separar dois processos que costumam ser confundidos: rastrear é o robô visitar a página e ler o código, enquanto indexar é decidir guardar aquela página no índice para que ela possa ranquear. O crawl budget diz respeito à primeira etapa, que é a porta de entrada para a indexação.
Como o Google decide o crawl budget: crawl rate e crawl demand
O Google descreve o orçamento de rastreamento como o encontro de dois componentes. Saber o que cada um significa ajuda a entender onde dá para agir:
| Componente | O que é e o que influencia |
|---|---|
| Limite de rastreamento (crawl rate) | O máximo de requisições que o robô faz sem sobrecarregar o servidor. Um site rápido e estável recebe o robô com mais frequência; um servidor lento ou cheio de erros faz o Google pisar no freio. |
| Demanda de rastreamento (crawl demand) | O quanto o Google quer visitar o site. Páginas populares, com links apontando para elas, e conteúdo que muda com frequência despertam mais demanda do que páginas paradas e ignoradas. |
Na prática, o crawl budget é o menor dos dois: não adianta ter um servidor potente se o Google não vê motivo para voltar, nem ter conteúdo desejado se o servidor cai a cada visita. Melhorar o rastreamento significa cuidar dos dois lados ao mesmo tempo.
Quando você precisa se preocupar com crawl budget
Para a maioria dos sites, o orçamento de rastreamento não é gargalo. O robô rastreia tudo o que precisa e ainda sobra. A conta muda quando o site cresce e passa a gerar muitas URLs. Preste atenção se o seu caso for um destes:
- sites grandes, com mais de dez mil páginas relevantes;
- lojas e catálogos que criam muitas URLs a partir de filtros e parâmetros de URL;
- portais de notícias e sites que publicam ou atualizam conteúdo o tempo todo;
- domínios com muitas páginas de baixa qualidade competindo pela atenção do robô.
Quando o rastreamento vira gargalo, o efeito é silencioso: páginas novas demoram a aparecer no Google e páginas atualizadas seguem exibindo a versão antiga. Segundo a Botify, em sites grandes e não otimizados o Google chega a rastrear, em média, só cerca de 40% das URLs estratégicas a cada mês, o que deixa boa parte do conteúdo importante sem visita do robô.
O que desperdiça o seu orçamento de rastreamento
Boa parte do crawl budget se perde em páginas que não deveriam consumir tempo do robô. Os ralos mais comuns são:
- Conteúdo duplicado: várias URLs com o mesmo conteúdo fazem o robô rastrear a mesma coisa de novo. Uma URL canônica bem definida concentra o esforço na versão certa.
- Cadeias de redirecionamento: uma cadeia de redirecionamentos obriga o robô a dar vários saltos para chegar ao destino, gastando rastreamento à toa.
- URLs infinitas de parâmetros: filtros de cor, tamanho e ordenação multiplicam endereços quase idênticos.
- Páginas de erro e soft 404: páginas quebradas ou com soft 404 consomem visitas sem entregar nada de útil.
- Conteúdo raso: muitas páginas de thin content diluem a atenção do robô entre endereços que ninguém procura.
Cada uma dessas visitas desperdiçadas é uma visita a menos para as páginas que realmente importam. Cortar o excesso é o primeiro passo para o robô gastar o orçamento onde vale a pena.
Como otimizar o crawl budget na prática
Otimizar o rastreamento é, acima de tudo, guiar o robô para o conteúdo certo e afastá-lo do lixo. Um bom roteiro:
- Bloqueie o inútil no robots.txt: use o robots.txt para impedir o rastreamento de áreas sem valor de busca, como carrinhos, filtros e páginas internas de sistema.
- Mantenha um sitemap limpo: o sitemap XML deve listar só as URLs que você quer indexadas, sem redirecionamentos nem páginas bloqueadas.
- Corrija redirecionamentos e erros: encurte cadeias de redirect e elimine links internos que apontam para páginas quebradas.
- Acelere o servidor: um site rápido eleva o limite de rastreamento; velocidade é parte do SEO técnico.
- Reforce os links internos: um bom link interno sinaliza ao robô quais páginas são prioritárias e ajuda a distribuir o rastreamento.
- Consolide conteúdo fraco: junte ou remova páginas rasas para concentrar o orçamento no que gera resultado.
Uma observação importante: bloquear uma página no robots.txt economiza rastreamento, mas não a tira do índice. Para remover uma página dos resultados, o caminho é o noindex, e não o bloqueio de rastreamento.
Como monitorar o rastreamento no Google Search Console
Você não precisa adivinhar como o Google trata o seu site. O Google Search Console traz o relatório de Estatísticas de rastreamento, que mostra quantas requisições o robô fez por dia, o tempo médio de resposta do servidor e quais tipos de arquivo e códigos de status ele encontrou.
Vale acompanhar alguns sinais: picos de erros de servidor, muito tempo gasto em páginas irrelevantes e páginas importantes rastreadas com pouca frequência. Para checar uma URL específica, a inspeção de URL revela quando o Google rastreou aquela página pela última vez e se ela foi indexada. Com esses dados em mãos, dá para agir com precisão em vez de no escuro.